How to develop a cloud service: ensure smooth operation and add features
If you use the well-known comparison, the development of a cloud service is a task similar to replacing an engine on a flying airplane. But there is no alternative - you will hopelessly lag behind if you do not constantly change. MySklad service has been constantly changing for 7 years. In this post we will talk about how this happens.

If your service works in B2B (that is, for companies, not individual users), forecasting its load is quite simple. She does not have unexpected jumps like a habraeffect. If we talk about our region - trade - during the year there are two well-known peaks: before the New Year holidays and March 8. Peaks amount to several tens of percent (and not several times).
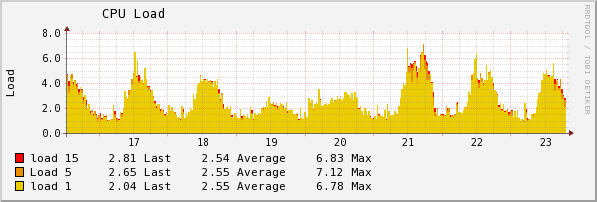
Since the load does not change much (in the picture - the actual load schedule of one of the servers), there is no great need for the elasticity that various PaaS give. Therefore, instead of Amazon EC2 or other cloud hosting, we rent ordinary physical dedicated servers. Apparently, with a stably high load, this is the optimal solution.
If everything goes well, the user base is constantly growing. This is a constant trend, each month the load and the volume of bases are increasing by 5-10%. In practice, this means that every few months we must either install new servers or improve the architecture of the service (or both).
But the main reason why you need to have a solid margin of load is errors. Some bugs appear on the production site along with updates. Most of all I remembered the exotic problem, when the not very intensive printing of the stack of traces in the log catastrophically slowed down the application on the server with AMD processors. (On servers with Intel, everything worked fine.)
Other errors patiently wait for their chance. In practice, most of the problems we got exotic patterns that looped the code for printing documents. Therefore, we determined the minimum margin in performance for all servers and components - 2-3 times. In most cases, it allows users to work normally, even if there are any problems inside.
In my opinion, there is no need to immediately prepare the architecture for super-high loads. In the B2B world, nothing happens instantly, and with smooth growth, there is time to gradually adapt the architecture to the growing load.
MySklad started as one monolithic Java EE application and one database. A few years after the launch, the only database server ceased to cope with the load. We said “ok” and divided the database into several physical servers. After some time, the application itself approached the load limit. We said “ok” and took to the separate server long and difficult tasks - data import and export, API. After some time, we spread the main application to several servers.
You don’t have to spend too much time preparing for future ultra-high loads. Most likely, then all the same, everything will have to be redone.
The development of architecture is most helped or hindered by technology. The right technology makes life simple and enjoyable. Wrong bring pain and suffering.
I will give an example. To combine several JVMs in a cluster, we used the built-in Infinispan distributed cache in JBoss . Up to a point, everything went well, but then (possibly due to an increase in load) regular crashes began. The problem was that about once a week, Infinispan lost contact between individual Java machines.
There are a lot of settings in Infinispan, and on the Internet there are tips on how to tweak these settings to solve the same or similar problems. We spent several months trying out the reasonable options. Cache continued to fall off regularly.
The solution to the problem was simple. In one week, we moved the cache implementation from Infinispan to Hazelcast . This implementation worked right away.
If the technology does not work, it is best to replace it as soon as possible.
An important task of product development is to keep it balanced. What does it mean?
Like any sufficiently mature product, MyStore has a hefty backlog of things that should have been done for a long time. So voluminous that working with it is quite difficult. In the next release, you can pull new features in a more or less random way, but how optimal is this?
The understanding that all features are clearly divided into three groups helps to significantly reduce chaos.
1) Platform features. Outwardly, they give nothing to users, and often interfere, because their release is potentially associated with the most severe glitches and brakes. Nevertheless, if you do not constantly implement platform improvements, soon enough the product will stagger on thin legs and will collapse heavily under an ever-increasing load.
2) Recycling functionality. They do not give new opportunities, but they tidy up what was done crookedly. Recycling causes massive suffering for users who are used to working the old way. All the same, they need to be made, because without them the product will quickly become hopelessly confusing and accessible for development only for the elite - geeks.
3) Really new features. Yes, less is more, minimum viable product steers, users buy a solution to their problems, and not a feature set and so on. But in the end, a particular product is chosen precisely because of a set of features that more or less accurately correspond to the tasks of the user. New features should appear continuously.
These three groups of features are already easier to balance. You just need to organize the development into three parallel threads. How are they better grouped into releases?
The main advice from our experience is to never combine new features and platform changes in one update. Such combined releases are too complex, difficult to prepare, and difficult to test. Therefore, we divide the releases into platform and functional.
A feature of platform releases is that under a big load, on real user data, something may go wrong. Therefore, we make them rollback. If problems arise, the old version returns in a few minutes and the development team begins to prepare a second attempt.
Functional releases are harder to make rollbacks. As a rule, they require changes in the database schema and data conversions, so returning the old version so simply will not work. But this is not necessary - a functional release is easier to qualitatively test.
Small life hack: massive updates are best rolled out over the weekend. On Saturday and especially Sunday, the service employs several times fewer users.
We have shown our approaches and methods for the continuous development of a successful cloud service. Once again I will repeat three important rules of work in the conditions of constant updates:
1. The main reason why it is necessary to have a substantial supply of resources under load is possible development errors, and not a hypothetical future increase in the number of users. Do not waste time preparing proactively for future ultra-high loads.
2. It makes no sense to try to make external libraries and components work for too long: if the technology does not work, it is best to replace it as soon as possible.
3. If you have already done everything and are ready for updates, never combine new features and platform changes in one release.
Loads
If your service works in B2B (that is, for companies, not individual users), forecasting its load is quite simple. She does not have unexpected jumps like a habraeffect. If we talk about our region - trade - during the year there are two well-known peaks: before the New Year holidays and March 8. Peaks amount to several tens of percent (and not several times).
Since the load does not change much (in the picture - the actual load schedule of one of the servers), there is no great need for the elasticity that various PaaS give. Therefore, instead of Amazon EC2 or other cloud hosting, we rent ordinary physical dedicated servers. Apparently, with a stably high load, this is the optimal solution.
If everything goes well, the user base is constantly growing. This is a constant trend, each month the load and the volume of bases are increasing by 5-10%. In practice, this means that every few months we must either install new servers or improve the architecture of the service (or both).
But the main reason why you need to have a solid margin of load is errors. Some bugs appear on the production site along with updates. Most of all I remembered the exotic problem, when the not very intensive printing of the stack of traces in the log catastrophically slowed down the application on the server with AMD processors. (On servers with Intel, everything worked fine.)
Other errors patiently wait for their chance. In practice, most of the problems we got exotic patterns that looped the code for printing documents. Therefore, we determined the minimum margin in performance for all servers and components - 2-3 times. In most cases, it allows users to work normally, even if there are any problems inside.
In my opinion, there is no need to immediately prepare the architecture for super-high loads. In the B2B world, nothing happens instantly, and with smooth growth, there is time to gradually adapt the architecture to the growing load.
MySklad started as one monolithic Java EE application and one database. A few years after the launch, the only database server ceased to cope with the load. We said “ok” and divided the database into several physical servers. After some time, the application itself approached the load limit. We said “ok” and took to the separate server long and difficult tasks - data import and export, API. After some time, we spread the main application to several servers.
You don’t have to spend too much time preparing for future ultra-high loads. Most likely, then all the same, everything will have to be redone.
Technology
The development of architecture is most helped or hindered by technology. The right technology makes life simple and enjoyable. Wrong bring pain and suffering.
I will give an example. To combine several JVMs in a cluster, we used the built-in Infinispan distributed cache in JBoss . Up to a point, everything went well, but then (possibly due to an increase in load) regular crashes began. The problem was that about once a week, Infinispan lost contact between individual Java machines.
There are a lot of settings in Infinispan, and on the Internet there are tips on how to tweak these settings to solve the same or similar problems. We spent several months trying out the reasonable options. Cache continued to fall off regularly.
The solution to the problem was simple. In one week, we moved the cache implementation from Infinispan to Hazelcast . This implementation worked right away.
If the technology does not work, it is best to replace it as soon as possible.
Releases
An important task of product development is to keep it balanced. What does it mean?
Like any sufficiently mature product, MyStore has a hefty backlog of things that should have been done for a long time. So voluminous that working with it is quite difficult. In the next release, you can pull new features in a more or less random way, but how optimal is this?
The understanding that all features are clearly divided into three groups helps to significantly reduce chaos.
1) Platform features. Outwardly, they give nothing to users, and often interfere, because their release is potentially associated with the most severe glitches and brakes. Nevertheless, if you do not constantly implement platform improvements, soon enough the product will stagger on thin legs and will collapse heavily under an ever-increasing load.
2) Recycling functionality. They do not give new opportunities, but they tidy up what was done crookedly. Recycling causes massive suffering for users who are used to working the old way. All the same, they need to be made, because without them the product will quickly become hopelessly confusing and accessible for development only for the elite - geeks.
3) Really new features. Yes, less is more, minimum viable product steers, users buy a solution to their problems, and not a feature set and so on. But in the end, a particular product is chosen precisely because of a set of features that more or less accurately correspond to the tasks of the user. New features should appear continuously.
These three groups of features are already easier to balance. You just need to organize the development into three parallel threads. How are they better grouped into releases?
The main advice from our experience is to never combine new features and platform changes in one update. Such combined releases are too complex, difficult to prepare, and difficult to test. Therefore, we divide the releases into platform and functional.
A feature of platform releases is that under a big load, on real user data, something may go wrong. Therefore, we make them rollback. If problems arise, the old version returns in a few minutes and the development team begins to prepare a second attempt.
Functional releases are harder to make rollbacks. As a rule, they require changes in the database schema and data conversions, so returning the old version so simply will not work. But this is not necessary - a functional release is easier to qualitatively test.
Small life hack: massive updates are best rolled out over the weekend. On Saturday and especially Sunday, the service employs several times fewer users.
Summary
We have shown our approaches and methods for the continuous development of a successful cloud service. Once again I will repeat three important rules of work in the conditions of constant updates:
1. The main reason why it is necessary to have a substantial supply of resources under load is possible development errors, and not a hypothetical future increase in the number of users. Do not waste time preparing proactively for future ultra-high loads.
2. It makes no sense to try to make external libraries and components work for too long: if the technology does not work, it is best to replace it as soon as possible.
3. If you have already done everything and are ready for updates, never combine new features and platform changes in one release.