vSAN in a VMware-based cloud

The tasks of data storage and access are a pain point for any information system. Even a well-designed storage system (hereinafter SHD) during operation identifies problems associated with performance degradation. The complex of scaling problems deserves special attention when the amount of resources involved approaches the established limits set by the storage system developers.
The fundamental cause of these problems is the traditional architecture, based on a tight connection to the hardware characteristics of the used storage devices. Most clients still choose the method of storing and accessing data based on the characteristics of physical interfaces (SAS / SATA / SCSI), rather than the actual needs of the applications used.
A dozen years ago, this was a logical decision. System administrators carefully selected storage devices with the required specification, such as SATA / SAS, and expected to receive a performance level based on the hardware capabilities of the disk controllers. The battle was both for the volume of RAID controller caches and for options that prevent data loss. Now this approach to solving the problem is not optimal.
In the current environment, when choosing a storage system, it makes sense to start not from physical interfaces, but from performance expressed in IOPS (the number of I / O operations per second). Using virtualization allows you to flexibly use existing hardware resources and guarantee the required level of performance. For our part, we are ready to provide resources with the characteristics that the application really needs.
Storage Virtualization
With the development of virtualization systems, it was necessary to find an innovative solution for storing and accessing data, while at the same time providing fault tolerance. This was the starting point for the creation of SDS (Software-Defined Storage). To meet business needs, such storage facilities were designed with the separation of software and hardware.
The SDS architecture is completely different from the traditional one. The storage logic has become abstract at the software level. The organization of storage has become easier due to the unification and virtualization of each of the components of such a system.
What is the main factor hindering the implementation of SDS everywhere? This factor most often turns out to be an incorrect assessment of the needs of the applications used and an incorrect assessment of risks. For businesses, the choice of solution depends on the cost of implementation, based on the current consumed resources. Few people think what will happen when the amount of information and the required performance exceed the capabilities of the chosen architecture. Thinking on the basis of the methodological principle of “one should not multiply existing without need,” better known as the “Occam's Blade”, determines the choice in favor of traditional solutions.
Only a few understand that the need for scaling and reliability of data storage is more important than it seems at first glance. Information is a resource, and therefore, the risk of its loss must be insured. What happens when a traditional storage system fails? You will need to use the warranty or buy new equipment. And if the storage system is discontinued or has its “life span” (the so-called EOL - End-of-Life) ended? This can be a “black day” for any organization that cannot continue to use its own personal services.
There are no systems that would not have a single point of failure. But there are systems that can easily survive the failure of one or more components. Both virtual and traditional storage systems were created taking into account the fact that sooner or later a failure will occur. Here are just the “limit of durability” of traditional storage systems laid down by hardware, but in virtual storage systems it is defined in the software layer.
Integration
Drastic changes in the IT-infrastructure is always an undesirable phenomenon, fraught with downtime and loss of funds. Only a smooth introduction of new solutions makes it possible to avoid negative consequences and improve the work of services. That is why Selectel has developed and launched a cloud based on VMware , a recognized leader in the virtualization market. The service created by us will allow each company to solve the whole complex of infrastructure problems, including data storage.
We will talk about how we decided the issue with the choice of storage system, as well as what advantages this choice gave us. Of course, both traditional storage systems and SDS were considered. In order to clearly understand all aspects of exploitation and risks, we suggest delving into the topic in detail.
At the design stage, the following requirements were imposed on the storage system:
- fault tolerance;
- performance;
- scaling;
- the ability to guarantee the speed of work;
- correct work in the VMware ecosystem.
The use of traditional hardware solutions could not provide the required level of scaling, since it is impossible to constantly increase the storage capacity due to the limitations of the architecture. Also of great difficulty was the reservation at the level of the whole data center. That is why we paid attention to SDS.
There are several software solutions on the SDS market that would be suitable for building a cloud based on VMware vSphere. Among these solutions include:
- Dell EMC ScaleIO;
- Datacore Hyper-converged Virtual SAN;
- HPE StoreVirtual.
These solutions are suitable for use with VMware vSphere, but are not embedded in the hypervisor and run separately. Therefore, the choice was made in favor of VMware vSAN. Let us consider in detail what the virtual architecture of such a solution looks like.
Architecture
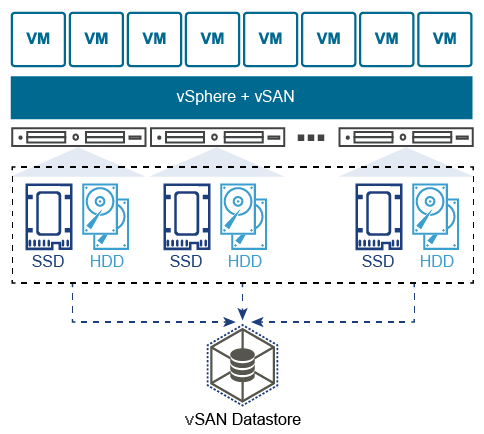
The image is taken from official documentation
. Unlike traditional storage systems, all information is not stored at any one point. Virtual machine data is evenly “spread” between all hosts, and scaling is done by adding hosts or installing additional disk drives on them. Two configuration options are supported:
- AllFlash configuration (only solid-state drives, both for data storage and for cache);
- Hybrid configuration (magnetic storage media and solid-state cache).
The procedure for adding disk space does not require additional settings, for example, creating a LUN (Logical Unit Number, logical disk numbers) and setting up access to them. Once a host has been added to a cluster, its disk space becomes available to all virtual machines. This approach has several significant advantages:
- lack of binding to the equipment manufacturer;
- increased fault tolerance;
- ensuring data integrity in case of failure;
- single control center from the vSphere console;
- convenient horizontal and vertical scaling.
However, this architecture places high demands on the network infrastructure. To ensure maximum throughput, the network in our cloud is built on the Spine-Leaf model.
Network
The traditional three-tier network model (core / aggregation / access) has several significant drawbacks. A striking example is the limitations of Spanning-Tree protocols.
The Spine-Leaf model uses only two levels, with the following advantages:
- predictable distance between devices;
- traffic goes on the best route;
- ease of scaling;
- exclusion of restrictions of protocols of the L2 level.
A key feature of this architecture is that it is optimized to the maximum for “horizontal” traffic. Data packets pass through only one hop, which makes it possible to clearly estimate delays.
The physical connection is provided with several 10GbE links per server, the bandwidth of which is combined using an aggregation protocol. Thus, each physical host gets high speed access to all storage objects.
Data exchange is implemented using a proprietary protocol created by VMware, which allows ensuring fast and reliable storage network operation on Ethernet transport (from 10GbE and higher).
The transition to the object model of data storage allowed us to flexibly adjust the use of storage in accordance with the requirements of customers. All data is stored in the form of objects that are distributed in a certain way to the cluster hosts. Specify the values of some parameters that can be controlled.
fault tolerance
- FTT (Failures To Tolerate). Indicates the number of failures of hosts that the cluster is able to handle without interrupting normal operation.
- FTM (Failure Tolerance Method). The method of ensuring fault tolerance at the disk level.
a. Mirroring .
The image is taken from a VMware blog.
It is a complete duplication of an object, and the replicas are always on different physical hosts. The closest analogue of this method is RAID-1. Its use allows the cluster to regularly handle up to three failures of any components (disks, hosts, network loss, etc.). This parameter is configured by setting the FTT option.
By default, this option is set to 1, with 1 replica being created for the object (a total of 2 instances on different hosts). As the value increases, the number of instances will be N + 1. Thus, with a maximum value of FTT = 3, there will be 4 instances of the object on different hosts.
This method allows you to achieve maximum performance at the expense of efficient use of disk space. It is allowed to use both in the hybrid and AllFlash configurations.
b. Erasure Coding (analog RAID 5/6).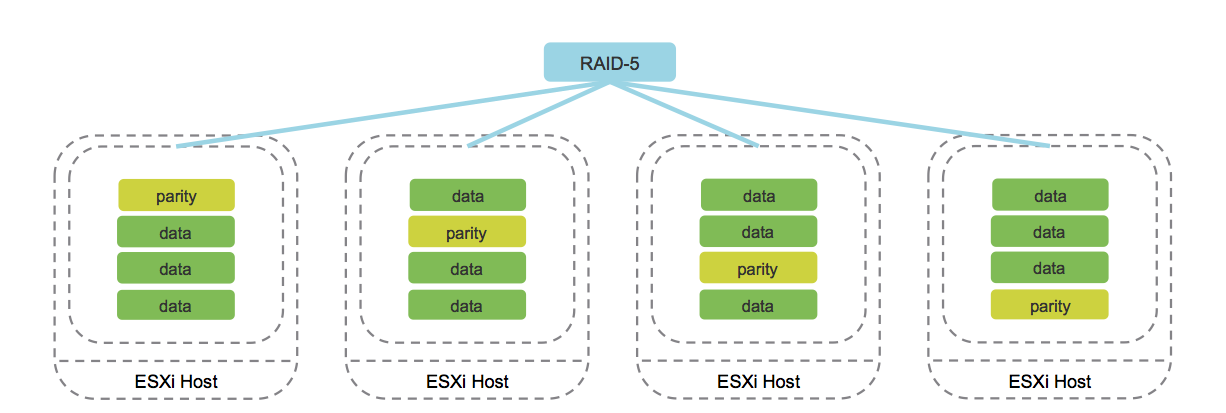
The image is taken from the cormachogan.com blog .
This method is supported exclusively on AllFlash configurations. In the process of writing each object, the corresponding parity blocks are calculated, which make it possible to unambiguously recover data when a failure occurs. This approach saves disk space significantly compared to Mirroring.
Of course, the work of this method increases the overhead costs, which are expressed in reduced productivity. However, given the performance of the AllFlash configuration, this drawback is leveled, making the use of Erasure Coding an acceptable option for most tasks.
In addition, VMware vSAN introduces the concept of “failure domains”, which is a logical grouping of server racks or disk baskets. As soon as the necessary elements are grouped, this results in the distribution of data among different nodes, taking into account the failure domains. This allows the cluster to survive the loss of a whole domain, since all corresponding object replicas will be located on other hosts in a different failure domain.
The minimum failure domain is a disk group, which are logically related disk drives. Each disk group contains two types of media - cache and capacity. The system allows using only solid-state disks as cache-carriers, and both magnetic and solid-state disks can act as capacity-carriers. Caching media helps speed up magnetic disk operations and reduce latency when accessing data.
Implementation
Let's talk about what limitations exist in the architecture of VMware vSAN and why they are needed. Regardless of the hardware platforms used, the architecture has the following limitations:
- no more than 5 disk groups per host;
- no more than 7 capacity-carriers in a disk group;
- no more than 1 cache in a disk group;
- no more than 35 capacity-carriers per host;
- no more than 9000 components per host (including witness components);
- no more than 64 hosts in the cluster;
- no more than 1 vSAN-datastore per cluster.
Why do you need it? As long as these limits are not exceeded, the system will operate with the declared capacity, maintaining a balance between capacity and storage. This ensures the correct operation of the entire virtual storage system as a whole.
In addition to these limitations, one important feature should be remembered. It is not recommended to fill more than 70% of the total storage. The fact is that when 80% is reached, the rebalancing mechanism starts automatically, and the storage system begins to redistribute data across all cluster hosts. The procedure is quite resource-intensive and can seriously affect the performance of the disk subsystem.
To meet the needs of a wide variety of customers, we have implemented three storage pools for ease of use in various scenarios. Let's look at each of them in order.
Fast drive pool
The priority for creating this pool was to obtain a storage that will provide maximum performance for hosting high-load systems. The servers in this pool use a pair of Intel P4600 as cache and 10 Intel P3520 for data storage. The cache in this pool is used in such a way that data is read directly from the media, and write operations occur through the cache.
A storage model called Erasure Coding is used to increase usable capacity and ensure fault tolerance. This model is similar to a regular RAID 5/6 array, but at the level of object storage. To eliminate the possibility of data corruption, vSAN uses a checksum calculation mechanism for each data block, 4K in size.
The check is performed in the background during read / write operations, as well as for “cold” data, access to which was not requested during the year. If there is a mismatch of checksums and, consequently, data corruption, vSAN will automatically restore the files by overwriting.
Hybrid drive pool
In the case of this pool, its main task is to provide a large amount of data, while providing a good level of fault tolerance. For many tasks, the speed of access to data is not a priority, the volume and storage cost are much more important. Using solid-state drives as such storage will be of unreasonably high cost.
This factor was the reason for the creation of a pool, which is a hybrid of the caching solid-state drives (as in other pools is Intel P4600) and enterprise-level hard drives developed by HGST. A hybrid workflow accelerates access to frequently requested data by caching read and write operations.
At the logical level, data is mirrored to eliminate loss in case of hardware failure. Each object is divided into identical components and the system distributes them to different hosts.
Disaster Recovery Pool

The main objective of the pool is to achieve the maximum level of resiliency and performance. The use of Stretched vSAN technology allowed us to spread storage between the data centers Flower-2 in St. Petersburg and Dubrovka-3 in the Leningrad region. Each server in this pool is equipped with a pair of high-capacity and high-speed Intel P4600 drives for cache operation and 6 pieces of Intel P3520 for data storage. At the logical level, these are 2 disk groups per host.
AllFlash configuration lacks a serious drawback - a sharp drop in IOPS and an increase in the queue of disk requests with an increased volume of random access data operations. Just like in a pool with fast disks, write operations go through the cache, and reading is done directly.
Now about the main difference from the other pools. The data of each virtual machine is mirrored inside one data center and at the same time synchronously replicated to another data center belonging to us. Thus, even a serious accident, such as a complete breakdown of connectivity between data centers will not become a problem. Even a complete loss of the data center will not affect the data.
An accident with a complete site failure - the situation is quite rare, but vSAN with honor can survive it without losing data. Guests of the event held by us SelectelTechDay 2018were able to see for themselves how the Stretched vSAN cluster experienced a complete site failure. Virtual machines became available within one minute after all the servers at one of the sites were turned off on power. All mechanisms worked exactly as planned, and the data remained intact.
The rejection of the usual data storage architecture entails a lot of changes. One of these changes was the emergence of new virtual "entities", which include the witness appliance. The point of this decision is to monitor the process of recording data replicas and determine which one is relevant. At the same time, the data itself is not stored on the witness components, only the metadata about the recording process.
This mechanism comes into effect in the event of a crash, when the replication process fails, which results in unsynchronized replicas.
To determine which of them contains relevant information, a quorum mechanism is used. Each component has a “voting right” and is assigned a number of votes (1 or more). The same “right to vote” has the witness components, which play the role of arbiters, in the event of a dispute.
A quorum is achieved only when a full replica is available for the object and the number of current “votes” is more than 50%.
Conclusion
Choosing VMware vSAN as a data storage system has become quite an important decision for us. This option has passed load testing and failover testing before it was included in our VMware-based cloud project.
According to the test results, it became clear that the declared functionality works as expected and satisfies all the requirements of our cloud infrastructure.
Is there something to tell based on your own experience with vSAN? Welcome to the comments.