MIT course "Computer Systems Security". Lecture 7: The Native Client Sandbox, Part 3
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture Course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mickens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security techniques based on recent scientific work. Topics include operating system (OS) security, features, information flow management, language security, network protocols, hardware security, and web application security.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Control of hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Sharing privileges” Part 1 / Part 2 / Part 3
Lecture 5: “Where do security systems come from” Part 1 / Part 2
Lecture 6: “Features” Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
In Rule C4There is one caveat. You cannot "jump" over the end of a program. The last thing you can jump to is the last instruction. So this rule guarantees that when the program is executed in the process “engine”, there will be no discrepancy.
Rule C5 says that there cannot be instructions larger than 32 bytes. We considered a certain version of this rule when we talked about the multiplicity of instruction sizes to 32 bytes, otherwise you can jump into the middle of the instruction and create a problem with the system call, which can “hide” there.
Rule C6claims that all available instructions can be disassembled from the very beginning. Thus, this ensures that we see each instruction and can check all the instructions that run when the program runs.
Rule C7 states that all direct jumps are correct. For example, you jump directly to that part of the instruction where the target is indicated, and although it is not a multiple of 32, it is still the correct instruction to which the disassembly is applied from left to right.

Audience: what is the difference between C5 and C3 ?
Professor: I think C5says that if I have an instruction of several bytes, it cannot cross the boundaries of adjacent addresses. Suppose I have a stream of instructions, and there is an address 32 and an address 64. So, the instruction cannot cross the border that is a multiple of 32 bytes, that is, it must not start with an address less than 64 and end with an address greater than 64.

This is what this says rule C5 . Because otherwise, having made a jump of multiplicity 32, you can get into the middle of another instruction, where it is not known what is happening.
And rule C3 is an analogue of this prohibition on the side of the jump. It states that whenever you jump, the length of your jump must be a multiple of 32.
C5also claims that everything in the address range that is a multiple of 32 is a safe instruction.
After reading the list of these rules, I had a mixed feeling, since I could not assess whether these rules are sufficient, that is, the list is minimal or complete.
So, let's think about the homework you have to complete. I think that in fact there is an error in the operation of the Native Client when executing some complicated instructions in the sandbox. I believe that they did not have the correct length coding, which could lead to something bad, but I can’t remember exactly what the error was.
Suppose a sandbox validator incorrectly gets the length of some kind of instruction. What bad can happen in this case? How would you use this slip?
Audience: for example, you can hide the system call or the return statement ret .
Professor: yes. Suppose there is some fancy version of the AND statement that you wrote down. It is possible that the validator was mistaken and considered that its length is 6 bytes with the actual length of 5 bytes.
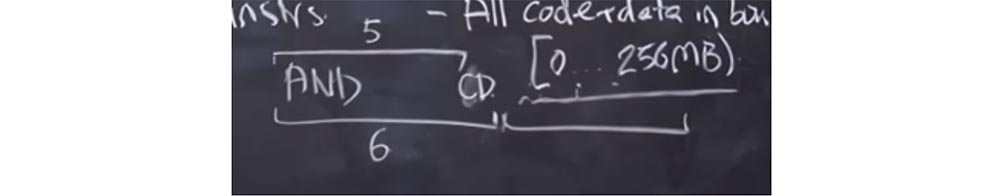
What will happen? The validator considers the length of this instruction to be 6 bytes and has another valid instruction behind it. But the processor, when launching the code, uses the real length of the instruction, i.e. 5 bytes. As a result, we have a free byte at the end of the instructionAND , where we could insert a system call and use it to our advantage. And if we insert a CD byte here , it will be like the beginning of another instruction. Next, we'll put something in the next 6-byte span, and it will be like an instruction that starts with the CD byte , although in fact it is part of the AND instruction . After that, we can make a system call and "escape" from the sandbox.
Thus, the Native Client validator must synchronize its actions with the actions of the CPU , that is, “guess” exactly how the processor will interpret each instruction. And this should be at every level of the sandbox, which is quite difficult to implement.
In fact, there are other interesting errors in the Native Client . One of them is the incorrect cleaning of the processor environment while jumping into the Trusted Service Runtime . I think we’ll talk about this in a second. But the Trusted Service Runtime is going to basically work with the same set of CPU registers that are designed to run untrusted modules. So if the processor forgets to clear something or reboot, the runtime may be tricked by considering the unreliable module a trusted application and doing something that it should not have done or that was not the intention of the developers.
So where are we now? At the moment, we understand how to disassemble all instructions and how to prevent the execution of prohibited instructions. Now let's see how we store memory and links for both code and data within the Native Client module .
For performance reasons, the Native Client guys are starting to use hardware support to make sure that storing memory and links doesn't actually cause a lot of overhead. But before considering the hardware support that they use, I want to hear suggestions, how could I do the same without the hardware support? Can we just provide access to all memory processes within the boundaries set by the machine earlier?
Lecture hall:You can instrument instructions to clear all high bits.

Professor: yes, that’s right. In fact, we see that we have this AND instruction here , and every time, for example, we jump somewhere, it clears the low bits. But if we want to keep all possible code that runs within the lower 256 MB, you can simply replace the first attribute of f at 0 and instead of $ 0xffffffe0 get $ 0x0fffffe0 . This clears the low bits and sets an upper limit of 256 MB.
Thus, this does exactly what you offer, making sure that whenever you jump, you are within 256 MB. And the fact that we are doing the disassembly also makes it possible to verify that all direct jumps are within reach.
The reason why they do not do this for their code is that on the x86 platform you can very efficiently encode AND , where all the upper bits are 1. This results in the existence of a 3-byte instruction for AND and a 2-byte instruction for the jump. Thus, we have an additional expense of 3 bytes. But if you need a non unit high bit like this 0 instead of f, then you suddenly have a 5-byte instruction. Therefore, I think that in this case they are worried about overhead.
Audience: Is there a problem with the existence of some instructions that increment the version you are trying to get? That is, you can say that your instruction may have a constant bias or something like that?
Professor: I think so. You will probably forbid instructions that jump to some complex address formula and will only support instructions that jump to this value directly, and this value always gets AND .
Audience: it is more necessary for access to memory than ...
Professor: yes, because it is just code. And to access memory on the platformx86 there are many strange ways to access a specific memory location. Usually, you must first calculate the memory location, then add an additional AND, and only then do access. I think this is the real reason for their concern about the decline in performance due to the use of this toolkit.
On the x86 platform , or at least on the 32-bit platform described in the article, they use hardware support instead of restricting the code and address data referencing untrusted modules.
Let's see how it looks before figuring out how to use the NaCl modulein the sandbox. This hardware is called segmentation. It arose even before the x86 platform got a swap file. On the x86 platform, a supported hardware table exists during the process. We call it the table of segment descriptors. It is a bunch of segments numbered from 0 to the end of a table of any size. This is something like a file descriptor on Unix , except that each entry consists of 2 values: the base base and the lenght length .
This table tells us that we have a pair of segments, and whenever we refer to a specific segment, this in a sense means that we are talking about a piece of memory that starts at the base address of the base and continues over the length length .

This helps us keep the boundaries of memory on the x86 platform , because each instruction, accessing the memory, refers to a specific segment in this table.
For example, when we execute mov (% eax), (% ebx) , that is, we move the memory value from a pointer stored in the EAX register to another pointer stored in the EBX register, the program knows what the starting and final addresses are, and will store the value in the second address.
But actually, on the x86 platform , when we talk about memory, there is an implicit thing called a segment descriptor, similar to a file descriptor in Unix . This is just an index in the descriptor table, and unless otherwise indicated, then each operation code contains a default segment.
Therefore, when you execute mov (% eax) , it refers to % ds , or to the data segment register, which is a special register in your processor. If I remember correctly, it is a 16-bit integer that points to this descriptor table.
And the same goes for(% ebx) - it refers to the same % ds segment selector . In fact, in x86 we have a group of 6 code selectors: CS, DS, ES, FS, GS and SS . The CS call selector is implicitly used to receive instructions. So if your instruction pointer points to something, then it refers to the one that selected the CS segment selector .
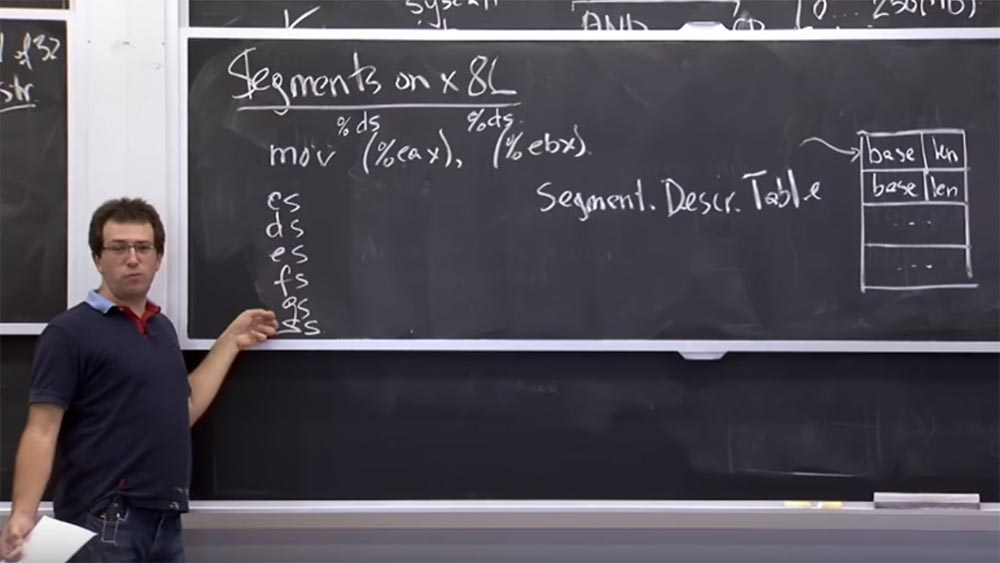
Most data references implicitly use DS or ES , FS and GS indicate some special things, and SS is always used for stack operations. And if you performpush & pop , they implicitly come from this segment selector. This is a rather archaic mechanics, but it turns out to be extremely useful in this particular case.
If you get access to some address, for example, in the selector % ds: addr , the hardware will redirect it to the operation with the table adrr + T [% ds] .base . This means that it will take the module length address from the same table. So every time you access memory, it has a database of segment selectors in the form of descriptor table entries, and it takes the address you specify and matches it with the length of the corresponding segment.
Audience: so why is it not used, for example, to protect the buffer?
Professor:Yes, that’s a good question! Could we use this to protect against buffer overflows? For example, for each buffer that we have, you can put the buffer base here, and there the buffer size.
Audience: what if you don’t need to put it in a table before you want to write it? You do not need to be there constantly.
Professor:Yes. Therefore, I think that the reason that this approach is not often used to protect against buffer overflows is because the number of entries in this table cannot exceed 2 in the 16th degree, because descriptors are 16 bits long, but actually in fact, a few more bits are used for other things. So in fact you can only place 2 in the 13th power of records in this table. Therefore, if you have in your code an array of data larger than 2 13 , an overflow of this table may occur.
In addition, it would be strange for the compiler to directly manage this table, because usually it is manipulated using system calls. You cannot directly write to this table, first you need to make a system call to the operating system, after which the operating system will place the record in this table. Therefore, I think that most compilers will simply not want to deal with such a complex memory buffer management system.

By the way, Multex uses this approach: it has 2 18 entries for various segments and 2 18records for possible offsets. And each common library fragment or memory fragment are separate segments. They are all checked for range and therefore cannot be used at a variable level.
Audience: Presumably, the constant need to use the kernel will slow down the process.
Professor: yes, that’s right. So we will have overhead due to the fact that when a new buffer is suddenly created on the stack, we need to make a system call to add it.
So how many of these elements actually use the segmentation mechanism? You can guess how it works. I think by default all these segments in x86have a base equal to 0 and a length of 2 to 32. Thus, you can access the entire range of memory that you want. Therefore, for NaCl, they encode base 0 and set the length to 256 megabytes. Then they point to all registers of 6 segment selectors in this record for the 256 MB area. Thus, whenever the equipment accesses the memory, it modifies it with an offset of 256 MB. So the ability to change the module will be limited to 256 MB.
I think you now understand how this hardware is supported and how it works, so you could end up using these segment selectors.
So what can go wrong if we just implement this plan? Can we jump out of the segment selector in an untrusted module? I think that one thing to be careful with is that these registers are like regular registers, and you can move values into and out of them. Therefore, you must make sure that the untrusted module does not distort these segment selector registers. Because somewhere in the descriptor table there may well be a record, which is also the source segment descriptor for a process that has a base of 0 and a length of up to 2 32 .

So if an unreliable module was able to change CS , or DS , or ES, or any of these selectors so that they begin to point to this original operating system, which covers all of your address space, then you can make a memory link to this segment and "jump out" of the sandbox.
Thus, the Native Client had to add a few more instructions to this forbidden list. I think that they forbid all instructions like mov% ds, es and so on. Therefore, once in the sandbox, you cannot change the segment to which some things referring to it refer. On the x86 platform , instructions for changing the segment descriptor table are privileged, but changing the ds, es themselves , etc. The table is completely unprivileged.
Audience: can you initialize the table so that zero length is placed in all unused slots?
Professor: yes. You can set the table length for something where there are no unused slots. It turns out that you really need this additional slot containing 0 and 2 32 , because the trusted runtime environment should start in this segment and gain access to the entire memory range. So this entry is necessary for the trusted runtime environment to work .
Audience: what is needed in order to change the length of the output of the table?
Professor: you must have root privileges. In Linux actually has a system called modify_ldt ()for a table of local descriptors, which allows any process to change its own table, that is, there is actually one table for each process here. But on the x86 platform this is more complicated, there is both a global table and a local table. A local table for a specific process can be changed.
Now let's try to figure out how we jump and jump from the Native Client execution process or jump out of the sandbox. What does it mean to jump out of us?

So, we need to run this trusted code, and this trusted code “lives” somewhere above the 256 MB limit. To jump there, we will have to undo all of the protections that the Native Client has installed. Basically they come down to changing these six selectors. I think that our validator is not going to apply the same rules for things located above the 256 MB limit, so this is quite simple.
But then we need to somehow jump into the trusted runtime runtime and reinstall the segment selectors to the correct values for this giant segment, covering the address space of the entire process - this range is from 0 to 2 32 . Such mechanisms exist in the Native Client , they called "trampolines» the trampoline and "jumps» springboards. They live in a low 64k module. The coolest thing is that these “trampolines” and “jumps” are pieces of code lying in the lower 64k of the process space. This means that this unreliable module can jump there, because it is a valid code address that is within the limits of 32 bits and within 256 MB. So you can jump onto this trampoline.
But the Native Client runtime must copy these “trampolines” from somewhere outside. Thus, the Native Client module was not allowed to support its own trampoline code, and the trampoline code comes from the trusted runtime runtime . As a result, it actually contains all these sensitive instructions, such as moving DS, CSand so on, that it is not allowed to have the most untrustworthy code.
Thus, in order to jump from the sandbox to a trusted runtime environment, to do something like maloс or create a thread, you need to jump to the "trampoline", which "lives" in a 32-byte offset.
Suppose it has an address of 4096 + 32 and it will have some instructions in order to undo these segment selectors. To do this, he, for example, will perform the operation mov% ds, 7 , that is, move the record to the ds register , while 7 will indicate an address space in the range from 0 to 2 32 . After moving the CS efficiently, you can jump into the trusted service runtime runtimeand it will be after 256 MB.

Thus, this jump is not allowed regularly, but everything will be in order, because here the jump is performed exactly to the trusted service runtime point that expects these jumps. After that, proper checks will be performed on the validity of the arguments and everything else that happens here. And we really can move DS here because we know that it is really safe and the code we are going to jump to is not going to do anything arbitrary or inappropriate with our untrusted module.
So why do these guys need to jump out of segments? For example, why not just put all these things on a trampoline? Perhaps this will be more time consuming?
Audience: we only have 64k.
Professor:Yes, that's right, because in reality you don’t have much space. Potentially, this may be enough to host maloс there, but the problem is not only in these 64k, but also in the 32 byte limit. And for trusted code, this is not a limitation, since the trusted code can do anything here, and it will not be checked.
The problem is that untrusted code can jump into every 32-byte offset, so each offset must have special arguments. Therefore, it will probably be difficult for you to write this code every 32 bytes, because every 32 bytes checks the arguments, values, and the like. So you have to jump from the trampoline and jump into trusted runtime within 32 bytes of code.

Here's how you jump out of the sandbox. To jump back to the sandbox, you need to undo these conversions, that is, install back DS, CS and so on. The hardest part here is that if you are outside this 256 megabyte limit, but working inside trusted runtime , you cannot reset these registers. Otherwise, then you will be able to access any memory in your outer space.
To do this, they use a second tool called a springboard, which, as it allows you to jump from trusted runtime beyond 256 MB back to the Native Client module . The springboard reloads the DS register , for example, with the function mov% ds, 7resets the other arguments and jumps to the address that trusted runtime wants to return to the untrusted module. This is the procedure for returning to the sandbox. The only difficulty is that the untrusted code does not jump onto the “springboard” itself, because after this something strange may happen.
Therefore, the developers placed the halt stop instruction in the first byte of the 32-byte sequence of the springboard. So if you jump to the beginning of the “springboard”, then stop immediately. At the same time, the trusted runtime trusted runtime is about to go past this first byte, go to 1 and take a jump back.

But only trusted service runtime can perform this operationbecause she regularly checks that nothing else will be allowed to do this.
Audience: is the “springboard” itself in an unreliable module?
Professor: "springboard" is in the range from 0 to 256 MB of an unreliable module. But in fact, it lives in a 64-bit piece at the very beginning of the module, that is, in the part where nothing from the “binary” downloaded by you from any website can get. It is added there by the Native Client when the module is first loaded into memory.
Audience: why not just create it at runtime?
Professor: yes, why don't we get it at runtime? What happens if the runtime allows the installation of a springboard? Why is this bad?
Audience: how then do we know where to return?
Professor: I think that in fact this jump is actually done on something like % eax , and trusted runtime says: “Oh, I want to return to this address”! The environment places it in the EAX register , jumps to the mov statement , and the springboard jumps to any EAX location that the trusted runtime runtime defines for it . So what happens if the module comes with its own “springboard”?
Audience: Well, you can do it like a natural-type jump, but it doesn't need to know anything about the descriptor table. This is hardware ...
Professor: yes, in fact, this is a very important instruction for the sandbox - the fact that we reload this descriptor in order to point to one of these limited descriptors in space from 0 to 2 32 . This is really important. Because if the module were allowed to install its own “springboard”, it could simply skip this part and not limit itself to a prerequisite to return to 256 MB.
Thus, as soon as you jumped through the “springboard”, you immediately gained access to the entire address space of the process. Thus, the “springboard” is part of the coercion mechanism, as if setting boundaries. Therefore, they do not want the “springboard” to be installed by the runtime.
Lecture hall:Is it possible to set a springboard beyond 256 megabytes?
Professor: I think they do not want to do this. This is due to the fact that you need to set the CS segment descriptor code in this limited segment and at the same time jump to some specific address. It’s easier to do this through the “springboard”, because first you jump to halt , then you run mov, then you set the CS value , but you can still execute the same code because the execution takes place within 256 MB.
I think that this is mainly due to the atomic primitives that the hardware provides you with. So you want to set up a whole bunch of DS segments , selector registers, CS registerand jump somewhere.
Probably, if you tried, you could come up with some sequence of x86 instructions that could do this outside the boundaries of the address space of the Native Client module .
So, see you next week and talk about web security.
The full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending it to your friends, a 30% discount for Habr users on a unique analogue of entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to divide the server? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free when paying for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to Build Infrastructure Bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros for a penny?