How to choose storage without shooting yourself in the foot
Introduction
It's time to buy storage. Which one to take, whom to listen to? Vendor A talks about vendor B, and there is also an integrator C, who tells the opposite and advises vendor D. In this situation, an experienced storage system architect will keep his head spinning, especially with all the new vendors and today's SDS and hyper-convergence.
So, how do you figure this out and not be stupid? We ( AntonVirtual Anton Zhbankov and korp Evgeny Elizarov) will try to tell about this in Russian in white.
The article has much in common, and in fact is an extension of the “ Design of a Virtualized Data Center””In terms of selecting storage systems and reviewing storage technology. We briefly consider the general theory, but we recommend that you familiarize yourself with this article.
What for
Often you can observe the situation when a new person comes to a forum or in a specialized chat room, such as Storage Discussions and asks the question: “here are two options for storage - I am offered ABC SuperStorage S600 and XYZ HyperOcean 666v4, what do you recommend?”
And someone begins to measure what features of the implementation of terrible and incomprehensible chips, which for an unprepared person, is a Chinese letter.
So, the key and very first question that you need to ask yourself long before comparing specifications in commercial offers is WHY? Why is this storage necessary?

The answer will be unexpected, and very much in the style of Tony Robbins - to store data. Thank you captain! Nevertheless, sometimes we go so far into the comparison of details that we forget why we do all this at all.
So, the task of the data storage system is to store and provide access to DATA with a given performance. We will start with the data.
Data
Data type
What kind of data do we plan to store? A very important issue that can delete many storage systems even from consideration. For example, it is planned to store videos and photos. You can immediately delete systems designed for random access by a small block, or systems with proprietary chips in compression / deduplication. It can be just excellent systems, we do not want to say anything bad. But in this case, their strengths will either become weak on the contrary (videos and photos are not compressed) or simply significantly increase the cost of the system.
Conversely, if the intended use is a loaded transactional DBMS, then excellent multimedia streaming systems capable of delivering gigabytes per second would be a bad choice.
Data volume
How much data do we plan to store? Quantity always grows into quality; you should never forget this, especially in our time of exponential growth in data volume. Petabyte class systems are no longer rare, but the more petabytes of volume, the more specific the system becomes, the less familiar the functionality of systems with random access of small and medium volumes. Trite because only the access statistics tables by blocks become larger than the available RAM on the controllers. Not to mention compression / tearing. Suppose we want to switch the compression algorithm to a more powerful one and squeeze out 20 petabytes of data. How long will it take: half a year, a year?
On the other hand, why bother with a garden if you need to store and process 500 GB of data? Only 500. Household SSDs (low DWPD) of this size cost nothing at all. Why build a Fiber Channel factory and buy a high-end external storage system with the cost of a cast-iron bridge?
What percentage of the total hot data? How uneven is the data load? This is where tiered storage technology or Flash Cache can really help if the amount of hot data is scanty compared to the total. Or vice versa, with a uniform load across the entire volume, often found in streaming systems (video surveillance, some analytics systems), such technologies will not give anything, and will only increase the cost / complexity of the system.
IP
The reverse side of data is an information system that uses this data. IP has a set of requirements that inherit data. For more information on IP, see “Designing a Virtualized Data Center”.
Failover / Availability Requirements
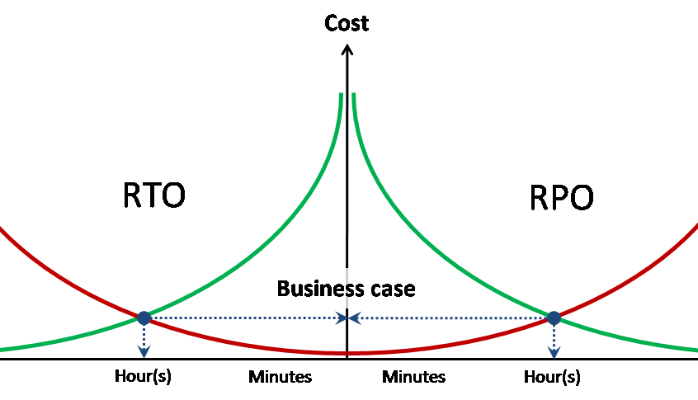
The requirements for fault tolerance / data availability are inherited from the IS using them and are expressed in three numbers - RPO , RTO , availability .
Availability - a share for a given period of time during which data is available for working with them. It is usually expressed in the amount of 9. For example, two nines per year means that availability is 99%, or 95 hours of inaccessibility per year are otherwise allowed. Three nines - 9.5 hours a year.
RPO / RTO - these are not total indicators, but for each incident (accident), in contrast to availability.
RPO- the amount of data lost during the accident (in hours). For example, if you back up once a day, then RPO = 24 hours. Those. In the event of an accident and complete loss of storage, data of up to 24 hours may be lost (from the time of the backup). Based on the RPO specified for the IS, for example, the backup schedule is written. Also, based on the RPO, you can understand how much synchronous / asynchronous data replication is needed.
RTO - time of service recovery (data access) after an accident. Based on the set RTO value, we can understand whether a metro cluster is needed, or unidirectional replication is enough. Do I need a multi-controller high-end storage class - too.
Performance requirements
Despite the fact that this is a very obvious question, most of the difficulties arise with it. Depending on whether you already have some kind of infrastructure or not, and ways to collect the necessary statistics will be built.
You already have a storage system and you are looking for a replacement for it or want to purchase another one for expansion. Everything is simple here. You understand what services you already have and which ones you plan to implement in the near future. Based on current services, you have the opportunity to collect performance statistics. Decide on the current number of IOPS and current delays - what are these indicators and are there enough for your tasks? This can be done both on the data storage system itself and on the part of the hosts that are connected to it.
Moreover, you need to watch not just the current load, but for some period (a month is better). See what are the maximum peaks in the daytime, what kind of load the backup creates, etc. If your storage or software for it does not give you a complete set of these data, you can use the free RRDtool, which can work with most of the most popular storage and switches and can provide you with detailed performance statistics. It is also worth looking at the load on the hosts that work with this storage system, on specific virtual machines, or what exactly works for you on this host.
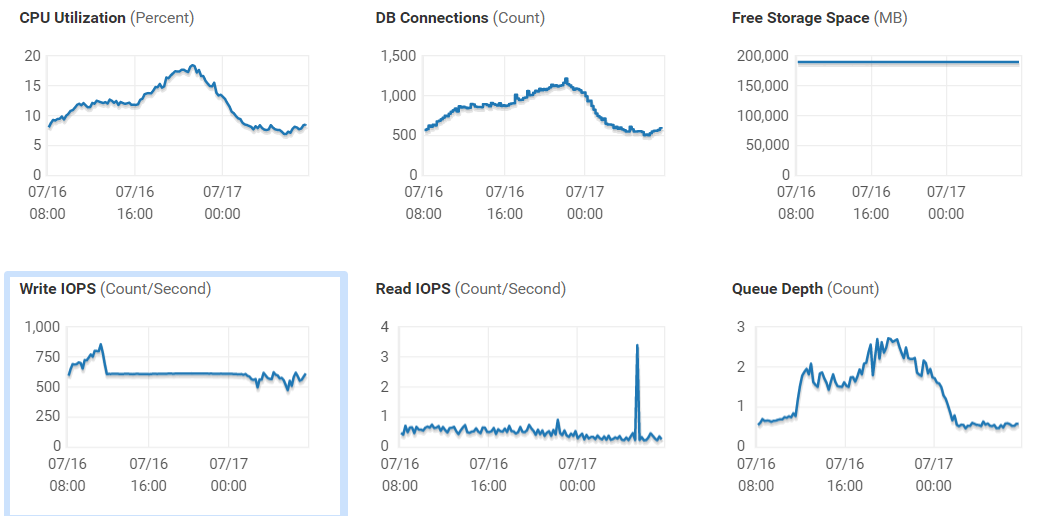
It should be noted separately that if the delays on the volume and the datastore that are on this volume differ quite a lot - you should pay attention to your SAN network, it is likely that there are problems with it and before acquiring a new system, you should deal with this issue , because the probability of increasing the performance of the current system is very high.
You are building the infrastructure from scratch, or you are acquiring a system for some kind of new service, the loads of which you are not aware of. There are several options: communicate with colleagues on specialized resources in order to try to find out and predict the load, contact an integrator who has experience implementing such services and who can calculate the load for you. And the third option (usually the most difficult, especially if it concerns self-written or rare applications), try to find out the performance requirements of the system developers.
And, attention, the most correct option from the point of view of practical application is a pilot on current equipment, or equipment provided for testing by a vendor / integrator.
Special requirements
Special requirements are all that do not fall under the requirements of performance, fault tolerance and functionality for the direct processing and provision of data.
One of the simplest special requirements for a data storage system is “alienated storage media”. And immediately it becomes clear that this data storage system should include a tape library or just a tape drive to which the backup is dumped. Then a specially trained person signs the tape and proudly carries it in a special safe.
Another example of special requirements is a protected shockproof performance.
Where
The second main component in the choice of a particular storage system is information about WHERE this storage system will stand. Starting from geography or climatic conditions, and ending with staff.
Customer
For whom is this storage planned? The question has the following grounds:
State customer / commercial.
A commercial customer does not have any restrictions, and is not even obliged to conduct tenders, except according to its own internal regulations.
The state customer is a different matter. 44 Federal Law and other delights with tenders and TK, which can be challenged.
The customer is under sanctions.
Well, the question here is very simple - the choice is limited only by the offers available for the customer.
Internal regulations / vendors / models allowed for purchase The
question is also extremely simple, but we must remember about it.
Where physically
In this part, we consider all issues with geography, communication channels, and the indoor climate.
Staff
Who will work with this storage? This is no less important than what SHD can do directly.
No matter how promising, cool and wonderful the storage system is from vendor A, there is probably little point in putting it if the staff can work only with vendor B, and there are no plans for further purchases and ongoing cooperation with A.
And of course, the flip side of the question is how accessible are trained personnel directly in the company and potentially in the labor market in this geographical location. For regions, the choice of storage systems with simple interfaces or the possibility of remote centralized management can make significant sense. Otherwise, at some point it can become painfully painful. The Internet is full of stories as a new employee who came in yesterday, a student yesterday, configured such that the whole office was killed.

Environment
Well, of course, an important question is what environment this storage will work in.
- What about power / cooling?
- What connection
- Where will it be mounted
- Etc.
Often, these issues are taken for granted and are not particularly addressed, but sometimes they can turn everything around exactly the opposite.
what
Vendor
Today (mid-2019), the Russian storage market can be divided into conditional 5 categories:
- Top division - well-deserved companies with a wide range from the simplest disk shelves to hi-end (HPE, DellEMC, Hitachi, NetApp, IBM / Lenovo)
- The second division is companies with a limited lineup, niche players, serious SDS vendors or rising newcomers (Fujitsu, Datacore, Infinidat, Huawei, Pure, etc.)
- The third division - niche solutions in the rank of low end, cheap SDS, good practice on ceph and other open projects (Infortrend, Starwind, etc.)
- SOHO segment - small and ultra-small storage systems at home / small office level (Synology, QNAP, etc.)
- Import-substituted storage systems - this includes both hardware of the first division with glued labels and rare representatives of the second (RAIDIX, let's give them an advance in the second), but mostly this is the third division (Aerodisk, Baum, Depo, etc.)
The division is rather arbitrary, and does not mean at all that the third or SOHO segment is bad and cannot be used. In specific projects with a clearly defined data set and load profile, they can work very well, far surpassing the first division in terms of price / quality ratio. It is important to first decide on the tasks, growth prospects, required functionality - and then Synology will serve you faithfully, and your hair will become soft and silky.
One of the important factors when choosing a vendor is the current environment. How many and which storage systems do you already have, what storage systems can engineers work with. Do you need another vendor, another point of contact, will you gradually migrate the entire load from vendor A to vendor B?
It is not necessary to produce entities beyond what is necessary.
iSCSI / FC / File
On the issue of access protocols, there is no consensus among engineers, and disputes resemble more theological discussions than engineering ones. But in general, the following points can be noted:
FCoE is more likely dead than alive.
FC vs iSCSI . One of the key advantages of FC in 2019 over IP storage, a dedicated factory for data access, is leveled by a dedicated IP network. FC has no global advantages over IP networks and IP can be used to build storage systems of any load level, up to systems for heavy DBMSs for ABS of a large bank. On the other hand, the death of FC has been prophesied for several years, but something constantly interferes with this. Today, for example, some players in the storage market are actively developing the NVMEoF standard. Whether he shares the fate of FCoE - time will tell.
File accessalso is not something worthy of attention. NFS / CIFS perform well in productive environments and, when properly designed, have no more complaints than block protocols.
Hybrid / All Flash Array
Classic storage systems come in 2 types:
- AFA (All Flash Array) - Systems optimized for using SSD.
- Hybrid - allowing you to use both HDD and SSD, or a combination of both.
Their main difference is the supported storage efficiency technologies and the maximum level of performance (high IOPS and low latencies). Both those and other systems (in most of their models, not counting the low-end segment) can operate both block devices and file devices. The supported functionality and the younger models also depend on the system level; it is most often cut to a minimum level. You should pay attention to this when you study the characteristics of a particular model, and not just the capabilities of the entire line as a whole. Also, of course, its technical characteristics depend on the level of the system, such as the processor, the amount of memory, cache, the number and types of ports, etc. From the point of view of Management, AFA differs from hybrid (disk) systems only in matters of implementing mechanisms for working with SSD drives, and even if you use SSD in a hybrid system, this does not mean at all that you can get a level of performance at the AFA level of the system. Also, in most cases, inline mechanisms for efficient storage on hybrid systems are disabled, and their inclusion leads to a loss in performance.
Special Storage
In addition to general-purpose storage, focused primarily on operational data processing, there are special storage systems with key principles that are fundamentally different from the usual ones (low latency, a lot of IOPS):
Media.
These systems are designed for storage and processing of media files that are large in size. Acc. the delay becomes practically unimportant, and the ability to send and receive data in a wide band in many parallel streams comes to the fore.
Deduplicating storage for backups.
Since backups differ in friendliness, which is rare under ordinary circumstances (the average backup differs from yesterday by 1-2%), this class of systems extremely efficiently packs the data recorded on them within a fairly small number of physical media. For example, in some cases, data compression ratios can reach 200 to 1.
Object storage systems.
These storage systems do not have the usual volumes with block access and file balls, and most of all they resemble a huge database. Access to an object stored in such a system is carried out by a unique identifier or by metadata (for example, all objects in the JPEG format, with the creation date between XX-XX-XXXX and YY-YY-YYYY).
Compliance system .
Not so often found in Russia today, but it is worth mentioning them. The purpose of these storage systems is guaranteed data storage for compliance with security policies or regulatory requirements. In some systems (for example, EMC Centera), the function of prohibiting data deletion was implemented - as soon as the key is turned and the system goes into this mode, neither the administrator nor anyone else can physically delete the data already recorded.
Proprietary technology
Flash cache
Flash Cache is the common name for all proprietary technologies for using flash memory as a second-level cache. When using the flash cache, storage is usually calculated to provide a steady load from magnetic disks, while the peak cache serves the peak load.
It is necessary to understand the load profile and the degree of localization of calls to storage volume blocks. Flash cache is a technology for workloads with high localization of requests, and is practically not applicable for evenly loaded volumes (such as for analytics systems).
Two flash cache implementations are available on the market:
- Read Only. In this case, only read data is cached, and writing goes directly to the disks. Some manufacturers, such as NetApp, believe that writing to their storage system is optimal, and the cache will not help.
- Read / Write. Not only read but also write is cached, which allows you to buffer the stream and reduce the impact of RAID Penalty, and as a result, increase the overall performance for storage with not such an optimal write mechanism.
Tiering
Multilevel storage (tearing) is a technology of combining levels into a single disk pool with different performance, such as SSD and HDD. In the case of a pronounced non-uniformity of accesses to data blocks, the system will be able to automatically balance the data blocks by moving the loaded ones to a high-performance level, and the cold ones, on the contrary, to a slower one.
Hybrid systems of the lower and middle classes use tiered storage with moving data between levels on a schedule. At the same time, the multilevel storage block size of the best models is 256 MB. These features do not allow us to consider multilevel storage technology as a technology for increasing productivity, as it is mistakenly considered by many. Multilevel storage in lower and middle class systems is a technology for optimizing storage costs for systems with pronounced load unevenness.
Snapshot
No matter how much we talk about the reliability of storage, there are many opportunities to lose data that are not dependent on hardware problems. It can be like viruses, hackers or any other, inadvertent deletion / corruption of data. For this reason, backing up productive data is an integral part of the engineer’s work.
A snapshot is a snapshot of a volume at some point in time. When working with most systems, such as virtualization, databases, etc. we need to take a snapshot from which we will copy the data to a backup copy, while our IPs will be able to continue to work safely with this volume. But it is worth remembering - not all snapshots are equally useful. Different vendors have different approaches to creating snapshots related to their architecture.
CoW (Copy-On-Write). When you try to write a data block, its original content is copied to a special area, after which the recording is normal. This prevents data corruption inside the snapshot. Naturally, all these "parasitic" data manipulations cause an additional load on the storage system and for this reason vendors with a similar implementation do not recommend using more than a dozen snapshots, and do not use them at all on heavily loaded volumes.
RoW (Redirect-on-Write). In this case, the original volume is naturally frozen, and when you try to write a data block, the storage system writes data to a special area in free space, changing the location of this block in the metadata table. This allows you to reduce the number of rewriting operations, which ultimately eliminates the performance drop and removes restrictions on snapshots and their number.
There are also two types of snapshots with respect to applications:
Application consitent . At the time of creating the snapshot, the storage system pulls an agent in the consumer's operating system, which forcibly flushes disk caches from memory to disk and forces it to make this application. In this case, when restoring from a snapshot, the data will be consistent.
Crash consistent. In this case, nothing like this happens and the snapshot is created as is. In the case of recovery from such a snapshot, the picture is identical as if the power had suddenly turned off and there might be some loss of data that hung in the caches and did not reach the disk. Such snapshots are easier to implement and do not cause a performance drawdown in applications, but are less reliable.
Why do we need snapshots on data storage systems?
- Agentless backup directly from storage
- Creating test environments based on real data
- In the case of file storage, it can be used to create VDI environments through the use of storage snapshots instead of the hypervisor
- Ensuring low RPOs by creating scheduled snapshots at a frequency significantly higher than the backup frequency
Cloning
Cloning a volume - works on a similar principle as snapshots, but serves not only to read data, but to fully work with them. We are able to get an exact copy of our volume, with all the data on it, without making a physical copy, which will save space. Typically, volume cloning is used either in Test & Dev or if you want to check the functionality of some updates on your IS. Cloning will allow you to do this as quickly and economically as possible in terms of disk resources. only modified data blocks will be written.
Replication / Journaling
Replication is a mechanism for creating a copy of data on another physical storage system. Usually there is a proprietary technology for each vendor that works only within its own line. But there are also third-party solutions, including those working at the hypervisor level, such as VMware vSphere Replication.
The functionality of the proprietary technologies and their usability are usually far superior to the universal ones, but they are not applicable when, for example, you need to make a replica from NetApp to HP MSA.
Replication is divided into two subspecies:
Synchronous. In the case of synchronous replication, the write operation is sent to the second storage system immediately and execution is not confirmed until the remote storage system confirms it. Due to this, the access delay is increasing, but we have an exact mirror copy of the data. Those. RPO = 0 for the case of loss of primary storage.
Asynchronous . Write operations are performed only on the main storage system and are confirmed immediately, simultaneously accumulating in the buffer for packet transmission to the remote storage system. This type of replication is relevant for less valuable data, either for low-bandwidth channels or having high latency (typical for distances over 100 km). Respectively RPO = packet sending frequency.
There is often a logging mechanism with replicationdisk operations. In this case, a special area for logging is allocated and recording operations of a certain depth in time, or limited by the volume of the log, are stored. For certain proprietary technologies, such as EMC RecoverPoint, there is integration with system software that allows you to bind specific bookmarks to a specific journal entry. Due to this, it is possible to roll back the state of the volume (or create a clone) not just on April 23 11 hours 59 seconds 13 milliseconds, but at the time preceding “DROP ALL TABLES; COMMIT. ”
Metro cluster
Metro cluster is a technology that allows you to create bidirectional synchronous replication between two storage systems in such a way that from the side this pair looks like one storage system. It is used to create clusters with geographically spaced shoulders at metro-distances (less than 100 km).
Using an example in a virtualization environment, the metro cluster allows you to create a datastore with virtual machines that can be recorded directly from two data centers. In this case, a cluster is created at the hypervisor level, consisting of hosts in different physical data centers, connected to this datastore. Which allows you to do the following:
- Полная автоматизация процесса восстановления после смерти одного из датацентров. Без каких либо дополнительных средств все ВМ, работавшие в умершем датацентре, будут автоматически перезапущены в оставшемся. RTO = таймаут кластера высокой доступности (15 секунд для VMware) + время загрузки операционной системы и старта сервисов.
- Disaster avoidance или, по-русски, избежание катастроф. Если запланированы работы по электропитанию в датацентре 1, то мы заранее, до начала работ, имеем возможность мигрировать всю важную нагрузку в датацентр 2 нон стоп.
Виртуализация
Storage virtualization is technically the use of volumes from another storage system as disks. A virtualized storage system can simply push another's volume to the consumer as its own, simultaneously mirroring it to another storage system, or even create RAID from external volumes.
The classic representatives in the storage virtualization class are EMC VPLEX and IBM SVC. Well, of course, storage with virtualization - NetApp, Hitachi, IBM / Lenovo Storwize.
Why might you need it?
- Redundancy at the storage level. A mirror is created between the volumes, with one half being on HP 3Par and the other on NetApp. A virtualizer from EMC.
- Переезд данных с минимальным простоем между СХД разных производителей. Предположим, что данные надо мигрировать со старого 3Par, который пойдет под списание, на новый Dell. В этом случае потребители отключаются от 3Par, тома прокидываются под VPLEX и уже презентуются потребителям заново. Поскольку ни бита на томе не изменилось, работа продолжается. Фоном запускается процесс зеркалирования тома на новый Dell, а по завершению зеркало разбивается и 3Par отключается.
- Организация метрокластеров.
Компрессия / дедупликация
Compression and deduplication are those technologies that allow you to save disk space on your storage. It is worth mentioning right away that far from all data is subject to compression and / or deduplication in principle, while some types of data are compressed and deduplicated better, and some are vice versa.
There are 2 types of compression and deduplication :
Inline - data blocks are compressed and deduplicated before this data is written to disk. Thus, the system only calculates the hash of the block and compares it according to the table with the existing ones. Firstly, this is faster than just writing to disk, and secondly, we do not consume extra disk space.
Post- when these operations are carried out already on the recorded data that are on the disks. Accordingly, the data is first written to the disk, and only then, the hash is calculated and the extra blocks are removed and the disk resources are freed.
It is worth saying that most vendors use both types, which allows you to optimize these processes and thereby increase their efficiency. Most storage vendors have utilities available that allow you to analyze your data sets. These utilities work according to the same logic that is implemented in the storage system; therefore, the estimated level of efficiency will coincide. Also, do not forget that many vendors have efficiency guarantee programs that promise a level not lower than declared for a certain (or all) data types. And do not neglect this program, because by calculating the system for your tasks, taking into account the efficiency coefficient of a particular system, you can save on the volume. It is also worth considering that these programs are designed for AFA systems, but thanks to the purchase of a smaller volume of SSDs,
Model
And here we come to the right question.
“Here I am offered two options for storage - ABC SuperStorage S600 and XYZ HyperOcean 666v4, what do you recommend?
Turns to“ Here I am offered two options for storage - ABC SuperStorage S600 and XYZ HyperOcean 666v4, what do you advise?
Target load mixed VMware virtual machines with productive / test / development loops. Test = productive. 150 TB each with a peak performance of 80,000 IOPS 8kb block 50% random access 80/20 read-write. 300 TB for development, there is enough 50,000 IOPS, 80 random, 80 entries.
It is expected to be productive in a metro cluster RPO = 15 minutes RTO = 1 hour, development in asynchronous replication RPO = 3 hours, a test on one site.
There will be a 50TB DBMS, it would be nice for them to log.
We have Dell servers everywhere, old Hitachi storage systems are barely coping, we plan to increase 50% of the load in terms of volume and performance. ”
As they say, a correctly formulated question contains 80% of the answer.
Additional Information
What you should read more in the opinion of the authors
Books
- Olifer and Olifer “Computer Networks”. The book will help to systematize and possibly better understand how the data transmission medium works for IP / Ethernet storage systems.
- “EMC Information Storage and Management”. A great book on the basics of storage, why, how and why.
Forums and chats
- Storage Discussions
- Nutanix / IT Russian Discussion Club
- VMware User Group Russia
- Russian Backup User Group
General recommendations
Prices
Now, with regard to prices - in general, if they come across prices for storage systems, then usually it is a List price, from which each customer receives an individual discount. The discount size consists of a large number of parameters, so it is simply impossible to predict which final price your company will receive without a request to the distributor. But at the same time, recently low-end models began to appear in ordinary computer stores, such as, for example, nix.ru or xcom-shop.ru . In them you can immediately get the system you are interested in at a fixed price, like any computer components.
But I want to note right away that a direct comparison on TB / $ is not true. If you approach from this point of view, the simplest JBOD + server will be the cheapest solution, which will not provide the flexibility or reliability that a full-fledged, dual-controller storage system provides. This does not mean at all that JBOD is disgusting and dirty, just need to understand very clearly again how and for what purposes you will use this solution. You can often hear that there is nothing to break in JBOD, there is also one backplane. However, backplains can also fail. Everything breaks down sooner or later.
Total
Comparing systems with each other is necessary not only by price, or not only by productivity, but by the totality of all indicators.
Buy HDD only if you are sure that you need HDD. For low loads and incompressible data types, otherwise, it’s worthwhile to pay attention to the storage efficiency guarantee programs on SSDs that most vendors now have (and they really work, even in Russia), but it all depends on the applications and data that will be located on this storage.
Do not chase cheapness. Sometimes many unpleasant moments are hidden under these, one of which Yevgeny Elizarov described in his articles about Infortrend . And that, in the end, this cheapness can come to you sideways. Do not forget - "avaricious pays twice."