BLACK HAT conference. Survival lessons in a 300 Gbps DDOS attack. Part 2
- Transfer
BLACK HAT conference. Survival lessons in a 300 Gbps DDOS attack. Part 1 The
interesting thing about this attack was that they did not dare to attack us directly, but went along the chain of our providers. They began to attack upstream providers located above CloudFlare, and the source of the attack was indeed in London. At first I wasn't sure about that, but since Spamhaus was also in London, it was possible that the hacker wanted to put them in a shameful position. As I said, the technical mastermind of the attack seemed to be a teenager from London, perhaps in this way he could more effectively track the effect of his attack. This slide shows the BGP traffic route, which included a maximum of 30 next-hop transit nodes.
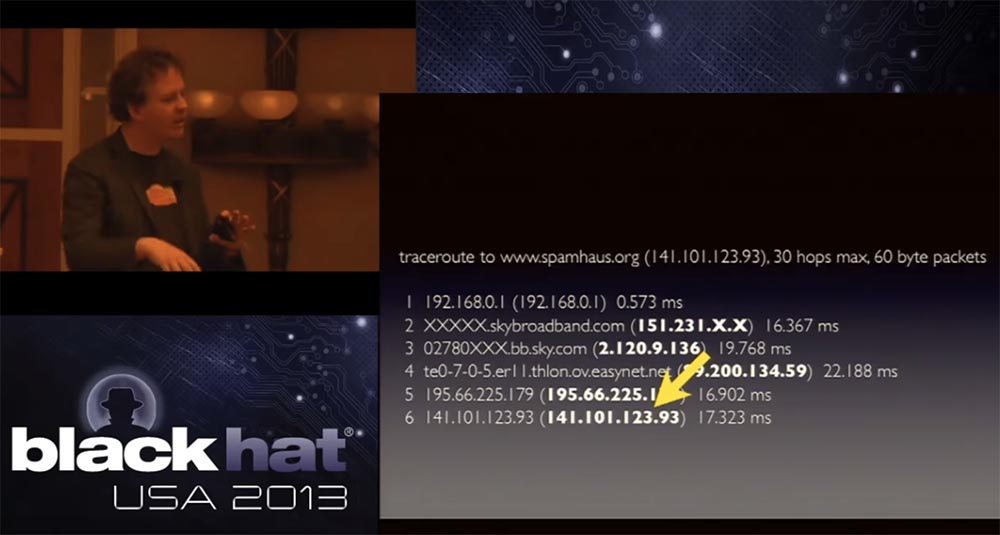
I hid the extensions of the addresses of the London broadband provider, the last hop is one of the Spamhaus IP addresses, there were several of them in our network. You can see how the traffic was routed; it is difficult to determine the exact path from the data, but it was sent to our equipment in London, where it hit 17 milliseconds after passing the border IP address of our network, which worked in London.
First, the attacker attacked this address, marked by an arrow, and since it uses distributed DNS, it hit London a little, a little Amsterdam and Frankfurt, the USA, Asia and a little Australia. Then the hacker realized that the attack was scattered and not effective, and decided to climb up the routing chain over additional parts of the infrastructure. Therefore, after the last IP address, it moved to the last but one IP address. Again, if you don’t know how Internet routing and connections work, I’ll say that some traffic is exchanging directly between networks when I connect my network directly to another network. In this particular case, traffic enters our network from the Sky network, passing through what is known as the London Internet Exchange, or LINX.
The attackers began to pass tons of traffic through LINX as a port. We have a LINX port with relatively modest capabilities, so if you send 300 gigs of traffic to the LINX port, you overload our port and other ports of this exchange. So the most reasonable solution for us was to drop the connection through this port, as soon as we saw that it was being attacked, and the traffic “flowed around” it in other ways.
The problem was that there was collateral damage that affected the remaining LINX ports, so that other providers of major Internet networks also had problems due to the fact that we were dropping traffic. It was rather unpleasant, and we subsequently worked with them to help them protect their networks.
The attack caused temporary regional disruptions, but we had a good opportunity to redirect traffic to other sites in order to create the ability to remain online for Spamhaus and all of our other clients. The attackers also affected our transit providers of a higher level, sending a whole bunch of traffic to people with whom we had contracts for network services. Their goal was to cause as much inconvenience to our customers as possible, so that parts of the network infrastructure that were not directly related to our network were affected.

It is possible that the attacks reached a higher level, but I have no data that would confirm this, but they attacked the basic routers operating in the core of various networks. In fact, this attack served as a giant pentest not only for our network, but also for the networks that surrounded us, the providers we used and the providers that these providers used. It turned out that thanks to this attack we conducted an audit of our vulnerabilities. Later we walked through various Internet exchanges such as London and implemented the best solutions in terms of setting up their networks in order to increase the effectiveness of countering such attacks. We found that all organization’s internal traffic should not be routed through the network’s border routers. Thus, if you do not want to hit one of these exchanges within the network of Internet exchanges, Its IP address should not be routed through these exchanges. Ideally, you should use 192.168, one of the unsolvable RFC 1918 addresses, which cannot be routed and allow traffic to pass through itself, that is, a network that does not require external access. This is the best thing you can do to counter this attack.
There are other things you can do, such as the Next Hop Self internal routing, to make sure that the traffic that is intended for transmission within the network will not use packets coming from outside. You must not only do this for your own network, but also convince upstream providers to do the same.
There is one more useful thing - boundary filtering for a specific IP address, based on an understanding of the operation of our application. For example, our application works with different protocols, and if we see a UDP packet not intended for our DNS server, it means that something went wrong.
Since then, we have segmented our networks in such a way that IP addresses for web servers are different from IP addresses for DNS servers, and we can ask our upstream providers to simply block all UDP traffic coming to that particular IP address. to ensure the security of our network segment. This separation of addresses allowed us to more aggressively filter high-level traffic.
The BGP Flowspec filter is our true friend, this is the protocol that was proposed by Cisco. Despite the fact that there are bugs in it, we use this protocol and prefer that transit providers also use it, because it allows us to transfer our rules to remote nodes of networks that affect our routes. This allows you to quickly respond to such an attack.
The nLayer three-tier architecture deserves special mention, and I want to express my deep gratitude to its creators from GTT, who did a tremendous job so that their network was particularly resistant to attacks. As soon as they saw the peaks of this attack, they quickly beat off traffic even from the boundaries of their network. Have you ever wondered how awesome it is to be a Tier-1, Layer3 or NTT provider? All their work is a solid weekend, because the first-level providers do not pay anyone for connections, and this also means that they cannot transfer transit to anyone. As we began to block the attack, turning off segments of our network, the impact concentrated on a small number of Tier-1 providers that were in the center of the attack, and a black hole was formed inside their network, into which all traffic rushed, because it had no place to go .
This is one of the reasons why you saw the Open Resolver Project created on the first Monday after the attack. The nLayer guys are a really tech-savvy team and they have been a big help to us. They treated us with understanding, and not just said: "Go away, you create too many problems for us." So, we have developed practical steps that you can take to make sure your networks are secure.

These are four recommendations, the first of which sounds silly, but obviously: first make sure that you are not part of the problem! I think many people have told you this in recent years. Just stop for a second and check that these two components are not running on your network.
The first is open resolvers. If they are in the company's IP address space, if your clients use them, you need to block them or limit the speed of traffic. It is even better to set up resolvers so that they receive only the traffic that comes directly from your network.
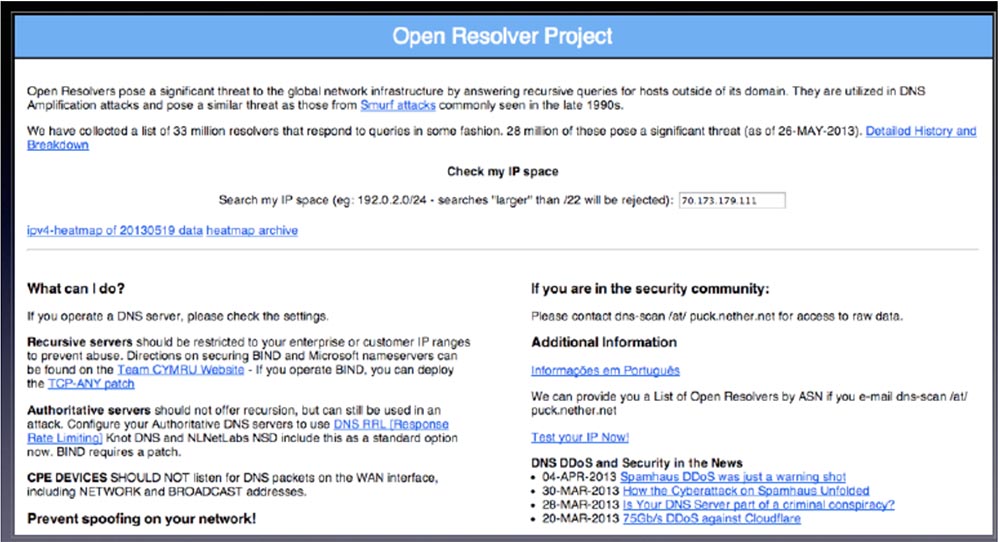
In this slide, you see my favorite article on The Register website, written by Trevor Pott. It is called "The recognition of an IT professional: how I helped the biggest DDoS attack."
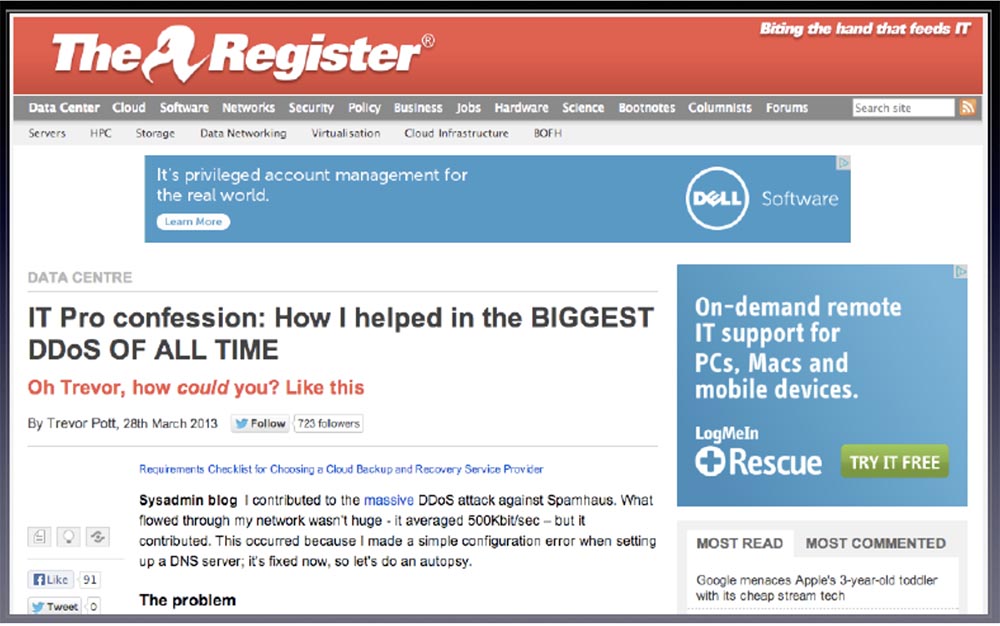
Trevor writes: “I thought I was doing everything right. But it turned out that I had an open resolver, and I saw traffic logs as requests hit Spamhaus. ” I know that there are people here who are responsible for the operation of very large networks that have open DNS resolvers. This way you contribute to the creation of the above problem, so I ask you - literally spend a second of time and get rid of them.
Second, make sure you are using BCP38. The guys from the iBall network have done a lot of work, but many of the people who are here, ensuring the operation of large networks, believe that the network is closed if they do not allow external access.
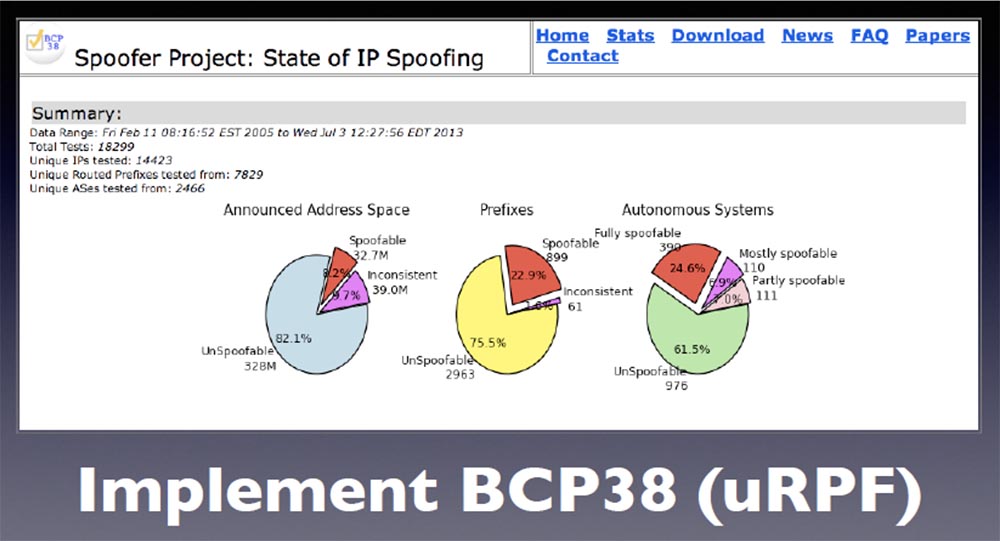
However, suppose that you have one compromised WordPress server on your network that can start spoofing source packages that are not intended for your network, and this will cause a big problem for the rest of the Internet.
The problem is open resolvers, these are 28 million resolvers, the number of which increases every week. We can overcome this problem only by joint efforts. You must set flags on your border routers to make sure they accept packets only from trusted sources within your network. If you do this, then deprive the attackers of the opportunity to use this vulnerability. The difficulty is to detect large compromised machines that operate on networks and that allow spoofing.
If you consider brute-force attacks on WordPress, and there are other attacks, for example, using a botnet network, then it will be difficult for you to guess that the reason lies in the ability to use spoofing.
Another recommendation is to use really reliable protocols. You can say: "Hey, I got this IP address and start the service via UDP protocol, and the TCP service and more ICMP traffic, and I will tie all these protocols to the same IP." I want to warn you that if there is a problem that limits your ability to respond flexibly to this type of attack, especially since you can easily segment the network so that each protocol works on its own IP address. Best of all, if you can filter upstream traffic. The goal of any of these attacks is not to stop the traffic inside your network, but to block it as close as possible to the traffic source, therefore giving someone the opportunity to block all UDP traffic directed to each IP other than the selected address, you will significantly reduce the attack surface,
Thus, separate protocols for individual IPs work effectively when interacting with upstream providers. You just ask them a question: “Hey, can you implement these types of filtering?”. By the way, one of the reasons that we, as suppliers, support Flowspec is that we can rightfully ask them: “Guys, do you support Flowspec?”, And if they answer “Yes”, the conversation is over, and we can deploy our own filters at the edge of the network as quickly as we want.
The third recommendation is the implementation of the ACL infrastructure, that is, the use of access control lists. I mean, a package cannot target your internal network if its source does not belong to this internal network. If a packet comes from your network or enters your network from a border router, it should not “travel” through the infrastructure of your internal network. There are many ways to implement this provision. You can apply filtering to allow some IP addresses to not reach the network’s boundaries, you can use Next Hop Self routing to prevent access to some internal addresses, you can use RFC 1918 protocols inside the network to make sure that your internal IPs are not used to address from the outside world.

It really can bring additional headaches, as it forces you to check the settings of the router, really use the VPN network, instead of pretending that you are using it, and so on. These are not the most popular solutions, but if they are not implemented, then the attacker can look into your network and target its individual segments in order to cause even more harm.
The fourth recommendation is that you should be well aware of your outbound upstream traffic. I want to emphasize once again that with this attack no complex applications or syn-packages were used, it was just a caveman with a heavy stick. In a sense, you should have more transit than the bad guy. It can generate 300 Gbit / s of traffic, and I am sure that few of those present can boast of networks with such a volume of traffic. This means that you must have a friend who has a lot of outgoing traffic, and by drawing him to cooperation, you are covering your back from such an attack. We are very selective about the outgoing traffic with which we work in order to be able to notice an attack of this kind in time.
The other day, I talked to the chief technical director of a major transit provider and asked him if he was going to sell me a transit, to which he replied - no, guys, as clients, you would receive only an extra headache.
However, we are looking for such traffic and even pay providers transit fees, which we use, because when attacks of this kind occur, we want to be able to call them and ask for help to mitigate the effects of the attack. You do not need to build networks with a capacity of 3-4-5 terabits, if you can distribute peak traffic across partner networks.
These do not have to be companies with powerful DDoS protection, they just have to use the nLayer architecture to do their job really well and help you when problems arise. Work closely with them to expand the boundaries of your network. Use a network configuration policy that allows you to join the boundary of their networks, and suppliers are ready to go for it if you have competent network providers. That's the whole story about the 300 gigabit attack, we still have about 10 minutes to answer your questions.

I ask you to use the microphone if you agree to stand in line to ask a question. Another innovation I forgot to say is that Blackhat organizers want to have feedback from the speaker, and if you “light up” your badge outside, they will pass your information to the NSA and also receive feedback. I was joking about the first part, but with respect to the second, everything is fair - you can use the feedback, so you can call me an idiot and ask any questions in general.
Question: which amplification protocols, other than UDP and 53, did you encounter while working with CloudFlare?
Answer: Are you asking if there were any other amplification protocols than those mentioned? We still observe the use of ICMP when performing the good old Smurf attacks, however, nothing is comparable with the scale of the attack that I told you about. So next year we will strongly insist that people do not use open resolvers, but use a legitimate, authorized DNS server. Use CloudFlare, Bind or UltraDNS to run your networks, and if you can list all the domains for which an authorized server is responsible, find domains that have very large lists of names, you can protect your network, because such a server has the ability to limit traffic speed We dedicated a lot of time to implementing this solution, and I’m happy to tell about this
Question: The botnet has not been used in this attack, but can you recommend resources that will make it possible to detect if the large networks that you manage do not use the botnet to carry out a DDoS attack?
Answer: it depends on where you are - for example, you can search for such tools in organizations that track the behavior of a botnet, and find one that fits your needs. If you need an open source project, I recommend Honeypot, which appeared several years ago. With it, we effectively monitor a significant part of the world's botnet networks, you can specify the range of your IP addresses and it will show if there are any malicious networks there. This is just one of many such projects. You can simply search for anomalous traffic patterns that are found on your network, so if you see gigabit traffic that goes to a single IP address, and there is no reasonable reason why this happens at a given point in time, then it’s probably traffic coming not from a web server, but from a network botnet.
Question: Google has one of the most popular open DNS resolvers, don't you think this can cause problems?
Answer: they did a lot of work on limiting traffic, and the best way to make sure of this is to use the same digANY request as I gave you as an example, and replace the PCCW IP address with address 888. Anyone present can send this request only one Once, repeat it will not work. So they implemented query limits very well. Another sensible thing you can use is the UDP-free flags, which solves many problems, you can limit the size of the answers you get back, thereby limiting the gain.
The question is: did you see transit providers deploying BGP Flowspec because you guys use it extensively, or if their network is not able to absorb a lot of traffic, do they refuse to use BGP Flowspec?
Answer: We try to work with customers who use BGP Flowspec, but if you see someone here with a Cisco badge, then this does not apply to them. They came up with a protocol that they never implemented, but we made enough noise to take our wishes into account when drawing up a network development plan. There are networks that do not support Flowspec throughout its length, and we deal with them from time to time. But we still prefer to deal with providers that use Juniper as the basis of the network, because there you can implement Flowspec. I hope that Cisco will also start supporting it in the next 12 months.
Question: Could you tell us a little about the experience of using Flowspec in your CloudFlare service?
Answer: I will say that this is a very busy thing. In the end, we find ourselves between the hammer and the anvil, because we need to use the most stable software version in our routers, but even the most stable version gives a lot of errors when working with Flowspec. So we created a whole intermediate layer of infrastructure that detects emerging bugs and tries to get around them. I do not really understand this, but if you are interested in the work of Flowspec, then I would be happy to connect you with more knowledgeable networkers from our team who have experience in this field. Once again, it is very important that your network rules can be extended to the adjacent networks of upstream providers.

Question: I use CloudFlare, I like this service and I follow your blog. I am afraid that you started something like an arms race, competing with the attacker in the capacity. Can it happen that you say: “Everything, we can no longer do this”?
Answer: I think that we are in a good position in this arms race, since we can quickly increase the power of our network. I think that the essence of this race is not in the design of the infrastructure, but in the number of networks that you can attract to your side in order to quickly increase the capacity. Of course, devices to protect against DDoS-attacks also play a role, but in the case of such an attack, you simply do not have any equipment with a port that can miss 300 Gbit / s. So it pushes people to create such huge networks like Akamai, which can mitigate the effects of such attacks. As the ultimate network service, we represent the world as a pile of things for which we buy “boxes” that can provide performance, security, and load balancing. We think of ourselves as a platform builder,
Probably, this can be regarded as an arms race, a rather painful process that still helps us more than hurts. And I know that the challenge posed by hackers to large networks contributes to the consolidation of providers and the further consolidation of networks. I think that the global network will center around a limited number of technically advanced providers, such as Akamai, Amazon, CloudFlare, and even Google, which, while otbryannyh struggling, will still be forced into this business. The question is, who else is able to ensure the functioning of such networks, if not they?
Question: I am grateful to you for drawing attention to the problem of open resolvers and BCP38, however, it seems that you are silent about the problem with the set of extensions for the DNSSec protocol ...
Matthew Prins: this is the reason why we do not use DNSSec!
Continuing the question: so, I would like to know if you are going to participate in the DNSSec fix, before they become widely used, or will you support alternative technologies?
Answer: this is a rather complicated question. In my opinion, DNSSec does not solve the problems for which it was created. Can I fix it? This is beyond our budget. I think we all would like to just turn the power switch - and DNSSec will work as it should, without making the world worse. I’m afraid that if we give impetus to the introduction of DNSSec, without taking care to minimize the damage it can cause to DNS servers, this will create a very big problem.
You can perform a similar enhancement without DNSSec, you can insert a whole bunch of text records, but, of course, it is much easier to find such large records using DNSSec. Sometimes we see people subscribing to Cloudflare services, create these giant DNS zone entries, and then use us as an amplifier, and we learned very well how to detect it. So the attackers' creative approach to using DNS servers will never cease to amaze me.
Question: Do you need to pay an upstream provider for the attacked traffic? This can be regarded as a continuation of the previous question.

Answer: yes, if, as a result of the attack, our traffic has increased so much that it exceeds the volumes stipulated in the contract with our upstream provider. However, we use proxy caching, so such cases occur very rarely. From the point of view of bandwidth, the advantage of CloudFlare is that usually we ourselves effectively cope with such attacks, so their consequences do not make it necessary to pay higher level providers for exceeding the amount of traffic coming from us.
Of course, such an exceptional attack, about which we spoke, cost us something. But we try to approach this not in the way that traditional providers approach during DNS DDoS: we get involved in this business, solve the problems caused by the attack, and then talk about money.
Question: Could it happen that you shift your expenses for paying for excess traffic as a result of a DDoS attack on your clients, motivating this decision by requiring you to pay too much money?
Answer: you underestimate how much money we have in the bank!
I thank everyone, I will be glad to talk to you guys, in another place, and now it’s time to give up this rostrum to the next speaker.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until spring for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
interesting thing about this attack was that they did not dare to attack us directly, but went along the chain of our providers. They began to attack upstream providers located above CloudFlare, and the source of the attack was indeed in London. At first I wasn't sure about that, but since Spamhaus was also in London, it was possible that the hacker wanted to put them in a shameful position. As I said, the technical mastermind of the attack seemed to be a teenager from London, perhaps in this way he could more effectively track the effect of his attack. This slide shows the BGP traffic route, which included a maximum of 30 next-hop transit nodes.
I hid the extensions of the addresses of the London broadband provider, the last hop is one of the Spamhaus IP addresses, there were several of them in our network. You can see how the traffic was routed; it is difficult to determine the exact path from the data, but it was sent to our equipment in London, where it hit 17 milliseconds after passing the border IP address of our network, which worked in London.
First, the attacker attacked this address, marked by an arrow, and since it uses distributed DNS, it hit London a little, a little Amsterdam and Frankfurt, the USA, Asia and a little Australia. Then the hacker realized that the attack was scattered and not effective, and decided to climb up the routing chain over additional parts of the infrastructure. Therefore, after the last IP address, it moved to the last but one IP address. Again, if you don’t know how Internet routing and connections work, I’ll say that some traffic is exchanging directly between networks when I connect my network directly to another network. In this particular case, traffic enters our network from the Sky network, passing through what is known as the London Internet Exchange, or LINX.
The attackers began to pass tons of traffic through LINX as a port. We have a LINX port with relatively modest capabilities, so if you send 300 gigs of traffic to the LINX port, you overload our port and other ports of this exchange. So the most reasonable solution for us was to drop the connection through this port, as soon as we saw that it was being attacked, and the traffic “flowed around” it in other ways.
The problem was that there was collateral damage that affected the remaining LINX ports, so that other providers of major Internet networks also had problems due to the fact that we were dropping traffic. It was rather unpleasant, and we subsequently worked with them to help them protect their networks.
The attack caused temporary regional disruptions, but we had a good opportunity to redirect traffic to other sites in order to create the ability to remain online for Spamhaus and all of our other clients. The attackers also affected our transit providers of a higher level, sending a whole bunch of traffic to people with whom we had contracts for network services. Their goal was to cause as much inconvenience to our customers as possible, so that parts of the network infrastructure that were not directly related to our network were affected.
It is possible that the attacks reached a higher level, but I have no data that would confirm this, but they attacked the basic routers operating in the core of various networks. In fact, this attack served as a giant pentest not only for our network, but also for the networks that surrounded us, the providers we used and the providers that these providers used. It turned out that thanks to this attack we conducted an audit of our vulnerabilities. Later we walked through various Internet exchanges such as London and implemented the best solutions in terms of setting up their networks in order to increase the effectiveness of countering such attacks. We found that all organization’s internal traffic should not be routed through the network’s border routers. Thus, if you do not want to hit one of these exchanges within the network of Internet exchanges, Its IP address should not be routed through these exchanges. Ideally, you should use 192.168, one of the unsolvable RFC 1918 addresses, which cannot be routed and allow traffic to pass through itself, that is, a network that does not require external access. This is the best thing you can do to counter this attack.
There are other things you can do, such as the Next Hop Self internal routing, to make sure that the traffic that is intended for transmission within the network will not use packets coming from outside. You must not only do this for your own network, but also convince upstream providers to do the same.
There is one more useful thing - boundary filtering for a specific IP address, based on an understanding of the operation of our application. For example, our application works with different protocols, and if we see a UDP packet not intended for our DNS server, it means that something went wrong.
Since then, we have segmented our networks in such a way that IP addresses for web servers are different from IP addresses for DNS servers, and we can ask our upstream providers to simply block all UDP traffic coming to that particular IP address. to ensure the security of our network segment. This separation of addresses allowed us to more aggressively filter high-level traffic.
The BGP Flowspec filter is our true friend, this is the protocol that was proposed by Cisco. Despite the fact that there are bugs in it, we use this protocol and prefer that transit providers also use it, because it allows us to transfer our rules to remote nodes of networks that affect our routes. This allows you to quickly respond to such an attack.
The nLayer three-tier architecture deserves special mention, and I want to express my deep gratitude to its creators from GTT, who did a tremendous job so that their network was particularly resistant to attacks. As soon as they saw the peaks of this attack, they quickly beat off traffic even from the boundaries of their network. Have you ever wondered how awesome it is to be a Tier-1, Layer3 or NTT provider? All their work is a solid weekend, because the first-level providers do not pay anyone for connections, and this also means that they cannot transfer transit to anyone. As we began to block the attack, turning off segments of our network, the impact concentrated on a small number of Tier-1 providers that were in the center of the attack, and a black hole was formed inside their network, into which all traffic rushed, because it had no place to go .
This is one of the reasons why you saw the Open Resolver Project created on the first Monday after the attack. The nLayer guys are a really tech-savvy team and they have been a big help to us. They treated us with understanding, and not just said: "Go away, you create too many problems for us." So, we have developed practical steps that you can take to make sure your networks are secure.
These are four recommendations, the first of which sounds silly, but obviously: first make sure that you are not part of the problem! I think many people have told you this in recent years. Just stop for a second and check that these two components are not running on your network.
The first is open resolvers. If they are in the company's IP address space, if your clients use them, you need to block them or limit the speed of traffic. It is even better to set up resolvers so that they receive only the traffic that comes directly from your network.
In this slide, you see my favorite article on The Register website, written by Trevor Pott. It is called "The recognition of an IT professional: how I helped the biggest DDoS attack."
Trevor writes: “I thought I was doing everything right. But it turned out that I had an open resolver, and I saw traffic logs as requests hit Spamhaus. ” I know that there are people here who are responsible for the operation of very large networks that have open DNS resolvers. This way you contribute to the creation of the above problem, so I ask you - literally spend a second of time and get rid of them.
Second, make sure you are using BCP38. The guys from the iBall network have done a lot of work, but many of the people who are here, ensuring the operation of large networks, believe that the network is closed if they do not allow external access.
However, suppose that you have one compromised WordPress server on your network that can start spoofing source packages that are not intended for your network, and this will cause a big problem for the rest of the Internet.
The problem is open resolvers, these are 28 million resolvers, the number of which increases every week. We can overcome this problem only by joint efforts. You must set flags on your border routers to make sure they accept packets only from trusted sources within your network. If you do this, then deprive the attackers of the opportunity to use this vulnerability. The difficulty is to detect large compromised machines that operate on networks and that allow spoofing.
If you consider brute-force attacks on WordPress, and there are other attacks, for example, using a botnet network, then it will be difficult for you to guess that the reason lies in the ability to use spoofing.
Another recommendation is to use really reliable protocols. You can say: "Hey, I got this IP address and start the service via UDP protocol, and the TCP service and more ICMP traffic, and I will tie all these protocols to the same IP." I want to warn you that if there is a problem that limits your ability to respond flexibly to this type of attack, especially since you can easily segment the network so that each protocol works on its own IP address. Best of all, if you can filter upstream traffic. The goal of any of these attacks is not to stop the traffic inside your network, but to block it as close as possible to the traffic source, therefore giving someone the opportunity to block all UDP traffic directed to each IP other than the selected address, you will significantly reduce the attack surface,
Thus, separate protocols for individual IPs work effectively when interacting with upstream providers. You just ask them a question: “Hey, can you implement these types of filtering?”. By the way, one of the reasons that we, as suppliers, support Flowspec is that we can rightfully ask them: “Guys, do you support Flowspec?”, And if they answer “Yes”, the conversation is over, and we can deploy our own filters at the edge of the network as quickly as we want.
The third recommendation is the implementation of the ACL infrastructure, that is, the use of access control lists. I mean, a package cannot target your internal network if its source does not belong to this internal network. If a packet comes from your network or enters your network from a border router, it should not “travel” through the infrastructure of your internal network. There are many ways to implement this provision. You can apply filtering to allow some IP addresses to not reach the network’s boundaries, you can use Next Hop Self routing to prevent access to some internal addresses, you can use RFC 1918 protocols inside the network to make sure that your internal IPs are not used to address from the outside world.
It really can bring additional headaches, as it forces you to check the settings of the router, really use the VPN network, instead of pretending that you are using it, and so on. These are not the most popular solutions, but if they are not implemented, then the attacker can look into your network and target its individual segments in order to cause even more harm.
The fourth recommendation is that you should be well aware of your outbound upstream traffic. I want to emphasize once again that with this attack no complex applications or syn-packages were used, it was just a caveman with a heavy stick. In a sense, you should have more transit than the bad guy. It can generate 300 Gbit / s of traffic, and I am sure that few of those present can boast of networks with such a volume of traffic. This means that you must have a friend who has a lot of outgoing traffic, and by drawing him to cooperation, you are covering your back from such an attack. We are very selective about the outgoing traffic with which we work in order to be able to notice an attack of this kind in time.
The other day, I talked to the chief technical director of a major transit provider and asked him if he was going to sell me a transit, to which he replied - no, guys, as clients, you would receive only an extra headache.
However, we are looking for such traffic and even pay providers transit fees, which we use, because when attacks of this kind occur, we want to be able to call them and ask for help to mitigate the effects of the attack. You do not need to build networks with a capacity of 3-4-5 terabits, if you can distribute peak traffic across partner networks.
These do not have to be companies with powerful DDoS protection, they just have to use the nLayer architecture to do their job really well and help you when problems arise. Work closely with them to expand the boundaries of your network. Use a network configuration policy that allows you to join the boundary of their networks, and suppliers are ready to go for it if you have competent network providers. That's the whole story about the 300 gigabit attack, we still have about 10 minutes to answer your questions.
I ask you to use the microphone if you agree to stand in line to ask a question. Another innovation I forgot to say is that Blackhat organizers want to have feedback from the speaker, and if you “light up” your badge outside, they will pass your information to the NSA and also receive feedback. I was joking about the first part, but with respect to the second, everything is fair - you can use the feedback, so you can call me an idiot and ask any questions in general.
Question: which amplification protocols, other than UDP and 53, did you encounter while working with CloudFlare?
Answer: Are you asking if there were any other amplification protocols than those mentioned? We still observe the use of ICMP when performing the good old Smurf attacks, however, nothing is comparable with the scale of the attack that I told you about. So next year we will strongly insist that people do not use open resolvers, but use a legitimate, authorized DNS server. Use CloudFlare, Bind or UltraDNS to run your networks, and if you can list all the domains for which an authorized server is responsible, find domains that have very large lists of names, you can protect your network, because such a server has the ability to limit traffic speed We dedicated a lot of time to implementing this solution, and I’m happy to tell about this
Question: The botnet has not been used in this attack, but can you recommend resources that will make it possible to detect if the large networks that you manage do not use the botnet to carry out a DDoS attack?
Answer: it depends on where you are - for example, you can search for such tools in organizations that track the behavior of a botnet, and find one that fits your needs. If you need an open source project, I recommend Honeypot, which appeared several years ago. With it, we effectively monitor a significant part of the world's botnet networks, you can specify the range of your IP addresses and it will show if there are any malicious networks there. This is just one of many such projects. You can simply search for anomalous traffic patterns that are found on your network, so if you see gigabit traffic that goes to a single IP address, and there is no reasonable reason why this happens at a given point in time, then it’s probably traffic coming not from a web server, but from a network botnet.
Question: Google has one of the most popular open DNS resolvers, don't you think this can cause problems?
Answer: they did a lot of work on limiting traffic, and the best way to make sure of this is to use the same digANY request as I gave you as an example, and replace the PCCW IP address with address 888. Anyone present can send this request only one Once, repeat it will not work. So they implemented query limits very well. Another sensible thing you can use is the UDP-free flags, which solves many problems, you can limit the size of the answers you get back, thereby limiting the gain.
The question is: did you see transit providers deploying BGP Flowspec because you guys use it extensively, or if their network is not able to absorb a lot of traffic, do they refuse to use BGP Flowspec?
Answer: We try to work with customers who use BGP Flowspec, but if you see someone here with a Cisco badge, then this does not apply to them. They came up with a protocol that they never implemented, but we made enough noise to take our wishes into account when drawing up a network development plan. There are networks that do not support Flowspec throughout its length, and we deal with them from time to time. But we still prefer to deal with providers that use Juniper as the basis of the network, because there you can implement Flowspec. I hope that Cisco will also start supporting it in the next 12 months.
Question: Could you tell us a little about the experience of using Flowspec in your CloudFlare service?
Answer: I will say that this is a very busy thing. In the end, we find ourselves between the hammer and the anvil, because we need to use the most stable software version in our routers, but even the most stable version gives a lot of errors when working with Flowspec. So we created a whole intermediate layer of infrastructure that detects emerging bugs and tries to get around them. I do not really understand this, but if you are interested in the work of Flowspec, then I would be happy to connect you with more knowledgeable networkers from our team who have experience in this field. Once again, it is very important that your network rules can be extended to the adjacent networks of upstream providers.
Question: I use CloudFlare, I like this service and I follow your blog. I am afraid that you started something like an arms race, competing with the attacker in the capacity. Can it happen that you say: “Everything, we can no longer do this”?
Answer: I think that we are in a good position in this arms race, since we can quickly increase the power of our network. I think that the essence of this race is not in the design of the infrastructure, but in the number of networks that you can attract to your side in order to quickly increase the capacity. Of course, devices to protect against DDoS-attacks also play a role, but in the case of such an attack, you simply do not have any equipment with a port that can miss 300 Gbit / s. So it pushes people to create such huge networks like Akamai, which can mitigate the effects of such attacks. As the ultimate network service, we represent the world as a pile of things for which we buy “boxes” that can provide performance, security, and load balancing. We think of ourselves as a platform builder,
Probably, this can be regarded as an arms race, a rather painful process that still helps us more than hurts. And I know that the challenge posed by hackers to large networks contributes to the consolidation of providers and the further consolidation of networks. I think that the global network will center around a limited number of technically advanced providers, such as Akamai, Amazon, CloudFlare, and even Google, which, while otbryannyh struggling, will still be forced into this business. The question is, who else is able to ensure the functioning of such networks, if not they?
Question: I am grateful to you for drawing attention to the problem of open resolvers and BCP38, however, it seems that you are silent about the problem with the set of extensions for the DNSSec protocol ...
Matthew Prins: this is the reason why we do not use DNSSec!
Continuing the question: so, I would like to know if you are going to participate in the DNSSec fix, before they become widely used, or will you support alternative technologies?
Answer: this is a rather complicated question. In my opinion, DNSSec does not solve the problems for which it was created. Can I fix it? This is beyond our budget. I think we all would like to just turn the power switch - and DNSSec will work as it should, without making the world worse. I’m afraid that if we give impetus to the introduction of DNSSec, without taking care to minimize the damage it can cause to DNS servers, this will create a very big problem.
You can perform a similar enhancement without DNSSec, you can insert a whole bunch of text records, but, of course, it is much easier to find such large records using DNSSec. Sometimes we see people subscribing to Cloudflare services, create these giant DNS zone entries, and then use us as an amplifier, and we learned very well how to detect it. So the attackers' creative approach to using DNS servers will never cease to amaze me.
Question: Do you need to pay an upstream provider for the attacked traffic? This can be regarded as a continuation of the previous question.
Answer: yes, if, as a result of the attack, our traffic has increased so much that it exceeds the volumes stipulated in the contract with our upstream provider. However, we use proxy caching, so such cases occur very rarely. From the point of view of bandwidth, the advantage of CloudFlare is that usually we ourselves effectively cope with such attacks, so their consequences do not make it necessary to pay higher level providers for exceeding the amount of traffic coming from us.
Of course, such an exceptional attack, about which we spoke, cost us something. But we try to approach this not in the way that traditional providers approach during DNS DDoS: we get involved in this business, solve the problems caused by the attack, and then talk about money.
Question: Could it happen that you shift your expenses for paying for excess traffic as a result of a DDoS attack on your clients, motivating this decision by requiring you to pay too much money?
Answer: you underestimate how much money we have in the bank!
I thank everyone, I will be glad to talk to you guys, in another place, and now it’s time to give up this rostrum to the next speaker.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until spring for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?