How we taught the robot to help support

The truth of life: even the perfect software will not save its developer from customer calls to technical support. And if on your software (talking about Parallels Plesk Panel) about 50% of all servers for web hosting in the world are running, messages to support are carried with terrible force. In addition to reports of errors and breakdowns of the Parallels Plesk Panel (alas, it does happen), support comes with questions regarding the implementation of custom configurations, the use of non-standard settings, and requests for features needed by customers for their implementation in the future. Customers do not always follow the development of the product and often just do not know that the subject of their request was implemented in some of the previous updates, and non-standard settings are already described in the Knowledge Base article for Parallels Plesk Panel. You just had to come up with
This material describes the experience of the Parallels Plesk Service Team (there is a twitter and a Facebook group ) - a structural unit of a large company. But I'm sure the article under the cut will be useful to startups who already have a finished product or service, but do not have a technical support service. And in which the product manager or the founder responds to user questions, doing this on the way to the office or before going to bed from home. Our system helped reduce the number of incoming tickets by 3-5%. Parallels Plesk Panel is thousands of man hours.
Why did we decide to do this?
During the existence of the Parallels Plesk Panel, the technical support team and the Parallels Plesk Service Team have accumulated a knowledge base on various problems and errors, on making some non-standard settings, as well as on where and in which updates some bug was fixed or a new one was added functionality. Knowledge is systematized and published as Knowledge Base articles . The knowledge base is being updated non-stop. Practice shows: even the best search and the most comprehensive data in the knowledge base does not guarantee that professional clients (in our case, hosting companies) will independently and quickly find a way to solve their problem with the help of relevant articles from the search results.
How to be We decided to bring the knowledge base closer to the users as soon as possible - to integrate it at different stages of detecting and reporting the problem by the client. In a nutshell: we had to come up with a system (in the future, for brevity, we will call it that) that would automatically offer the client solutions to his problem, taken from the knowledge base based on the description of this problem, which he wants to inform our support team.
The implementation of this system would reduce the number of incoming tickets to the technical support service due to the fact that the client would independently solve problems in the shortest possible time based on the solutions proposed by the system from the knowledge base. For hosters, whose business is largely tied to the uptime of client servers, the speed of "fixing" problems is a critical parameter.
Where did we start and why?
First, we created a signature database. Each specific article in the knowledge base has been assigned one or more signatures that most accurately and uniquely describe and present a particular problem. For instance:
| Signature | KB article |
|---|---|
1. Can't locate object method "get_msgid" via package "Mail::SpamAssassin::Bayes"2. Spamassassin training3. Train spamassassin4. Spamassassin train | kb.parallels.com/112919 |
1.2 Can't connect to local MySQL server through socket. Trying to establish test connection... ERROR 2002 (HY000) | kb.parallels.com/114289 |
1. Error code: (2) Could not find a valid SPF record | kb.parallels.com/6051 |
The accuracy and uniqueness of the signature are the main criteria for the success of the system.
For example, a
2012-09-11 05:41:13: (mod_fastcgi.c.2746) FastCGI-stderr: PHP Warning: date(): It is not safe to rely on the system's timezone settings.very bad signature, because the report from the client may have a different time
2012-09-11 05:41:13or a completely different number
mod_fastcgi.c.2746An article with a solution to this problem will not be found. Therefore, we tried to find a compromise between the uniqueness of the signature and its universality.
An example of a good signature:
FastCGI-stderr: PHP Warning: date(): It is not safe to rely on the system's timezone settingsQuite simple and monosyllabic signatures like FastCGI-stderr or SPF record lead to the fact that the corresponding database article will often be offered completely unreasonably in all cases where these combinations will be mentioned in client reports. Search accuracy drops, the custom meter rushes between several articles in KB, the time for solving the problem grows, the customers of the custom are nervous.
So, the signature database is created. We uploaded it to the Knowledge Base server, and it is ready to go. A tool was needed to use this base. We made it as a separate server for request APIs, with the code name Troubleshooter.
A reasonable question: why was the search system for static signatures chosen, and not a more advanced one? The answer is simple - this option is the fastest, and speed is the most critical parameter for our system. When a client arrives and fills out a ticket form with his text, he should not wait more than a few seconds until this text is checked by the system and the page with the scan results is loaded. After “running in” the system, we see how it is possible to improve the quality of the search in the signature database - for example, by using regular expressions or by using well-known semantic analyzers to form more relevant signatures.
Where and how is the system used?
Before talking about the mechanism of the system, it is necessary to describe three main options for its use:
- The most important and most basic way to use the system is to integrate the system into the ticket sending form on the corresponding page of the Parallels website.
- We have created and released utilities for executing them on the Linux or Windows command line. These utilities are essentially an offline version of the system and are add-ons for the signature database, which searches for known signatures in certain Parallels Plesk Panel log files and, based on the signatures found, offers a list of related Knowledge Base articles. This utility, called the Spider Tool, is described in more detail in the KB article and is discussed in the corresponding section of the Parallels forum .
- The third use of the system is intended for technical support when working with tickets.
More details on how each of the use cases work will be described below.
In the future, we will offer customomers another three possible options for using the system. First, we open the API for those customers who wish to integrate it into their infrastructure. The second is Troubleshooter's online form, through which anyone can enter any problem and analyze it for the existence of the corresponding article in the Knowledge Base, or download the entire log file and analyze it. And the third is integrating the system directly into the Parallels Plesk Panel interface.
How it works?
Let's take a closer look at how each of the three existing use cases works.
Option 1.
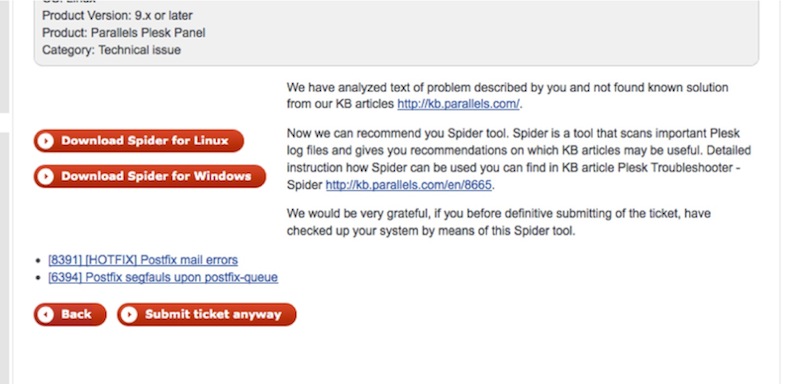
A client arrives on a special page of the Parallels website where calls are made to the support service, and after completing all the steps, he writes a text describing his problem. Then he presses the button "Send a ticket to customer support." But in fact, a ticket to support does not fly away immediately. At this stage, the ticket theme (what is written in the Subject field) and the ticket text are analyzed by the system for known signatures. Before the final ticket submission to the technical support service, the client is provided with Knowledge Base articles found based on the signature search. The client views these articles and solves their problem on their own using the proposed articles, without sending a ticket to the technical support service. If none of the articles proposed to him helped or no articles were found, the client can download the Spider Tool proposed for his platform and use option 2. Option 2 involves installing the Spider Tool to find problems on Plesk’s logs and get a list of relevant articles in KB to solve them. In case when none of the proposed options helped the client, he finally sends the ticket to the technical support using the Submit ticket anyway button. In the screenshot you can see how it looks in reality.
Option 2
Install and run the Spider Tool utility, which works from the command line. Here is its current version for Linux , and here is the version for Windows (both versions are downloaded by click). Distributions for both platforms contain the latest signature database and a special user space, which is designed to scan the most important Parallels Plesk Panel log files to find matches with the signature database. As a result, the user receives a list of problems found on his Plesk server with links to the corresponding Knowledge Base articles for independent solution of these problems.
The utility has many different options that expand the possibilities of its application. You can read more about it here .
Option 3
As stated in the description of the first option, the system scans the "body" and the subject line of the "Subject" letter from the client to the technical support service only at the stage of its creation. All subsequent customer correspondence with support takes place within the framework of the created ticket and can be scanned at any time by the technical support engineer manually using a special button in the Request Tracker. The system will analyze the entire correspondence taking into account new details of the problem that have appeared and offer the engineer those Knowledge Base articles that may be useful to him when working on a ticket.
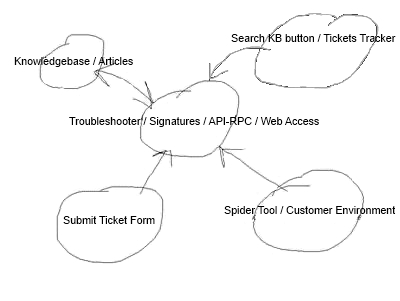
The scheme made on the knee looks very clumsy, but faithfully displays the mechanism of the system in all three variants of use:
conclusions
The system is in use relatively recently. With its integration, opportunities have been laid for the collection of statistical data. This data is collected and analyzed every month. At the moment, we are getting the values of several important metrics - the effectiveness and quality of Knowledge Base (KB Quality) articles and the effectiveness of the system itself (Ticket Avoidance, Accessibility).
According to the most preliminary data, the system allowed reducing the flow of incoming tickets by about 3-5%.
Its further improvement will significantly increase this indicator. In addition, it is planned to remove other metrics. For example, the rating (top) of Knowledge Base articles, after which the client did not click the final ticket submit button, for a more accurate and detailed assessment and analysis of the system’s work and the effectiveness of the existing articles for solving client problems.
Of course, there are more powerful systems to solve the problem. But they are usually designed for industrial search systems. Providing the necessary speed of text processing requires significant resources. In addition, we already had the existing Knowledge Base on the “Splash” of about 6 thousand articles, the modification of which would also require substantial resources. Therefore, we abandoned the use of existing expensive solutions as unjustified for our application, and created our own, fast, cheap and lightweight system, which even in the original version shows a very good result.
UPDATE: Today we launched for real use online I believe Troubleshooter. Use and ask questions!