Kubernetes Basics
In this publication I wanted to talk about an interesting, but undeservedly little described on Habr, the Kubernetes container management system.

Kubernetes is an open source project designed to manage the Linux container cluster as a single system. Kubernetes manages and runs Docker containers on a large number of hosts, as well as co-hosting and replicating a large number of containers. The project was started by Google and is now supported by many companies, including Microsoft, RedHat, IBM and Docker.
Google has been using container technology for over a decade. She began by launching more than 2 billion containers in one week. With the help of the Kubernetes project, the company shares its experience in creating an open platform designed for scalable container launch.
The project has two goals. If you use Docker containers, the following question arises about how to scale and run containers immediately on a large number of Docker hosts, and how to balance them. The project proposes a high-level API that defines the logical grouping of containers, which allows you to define container pools, balance the load, and also specify their location.
Nodes ( node.md ): A node is a machine in a Kubernetes cluster.
Pods ( pods.md ): Pod is a group of containers with shared partitions that run as a unit.
Replication Controllers ( replication-controller.md ): replication controller ensures that a certain number of "replicas" pods are launched at any given time.
Services ( services.md ): A service in Kubernetes is an abstraction that defines a logical unified set of pods and an access policy for them.
Volumes ( volumes.md ): Volume (section) is a directory, possibly with data in it, which is available in the container.
Labels (labels.md ): Labels are key / value pairs that are attached to objects, such as pods. Labels can be used to create and select sets of objects.
Kubectl Command Line Interface ( kubectl.md ): kubectl command line interface for managing Kubernetes.
A working Kubernetes cluster includes an agent running on nodes (kubelet) and wizard components (APIs, scheduler, etc), on top of a distributed storage solution. The above diagram shows the desired, in the end, state, although some things are still being worked on, for example: how to make kubelet (all components, in fact) run independently in the container, which will make the scheduler 100% connectable.
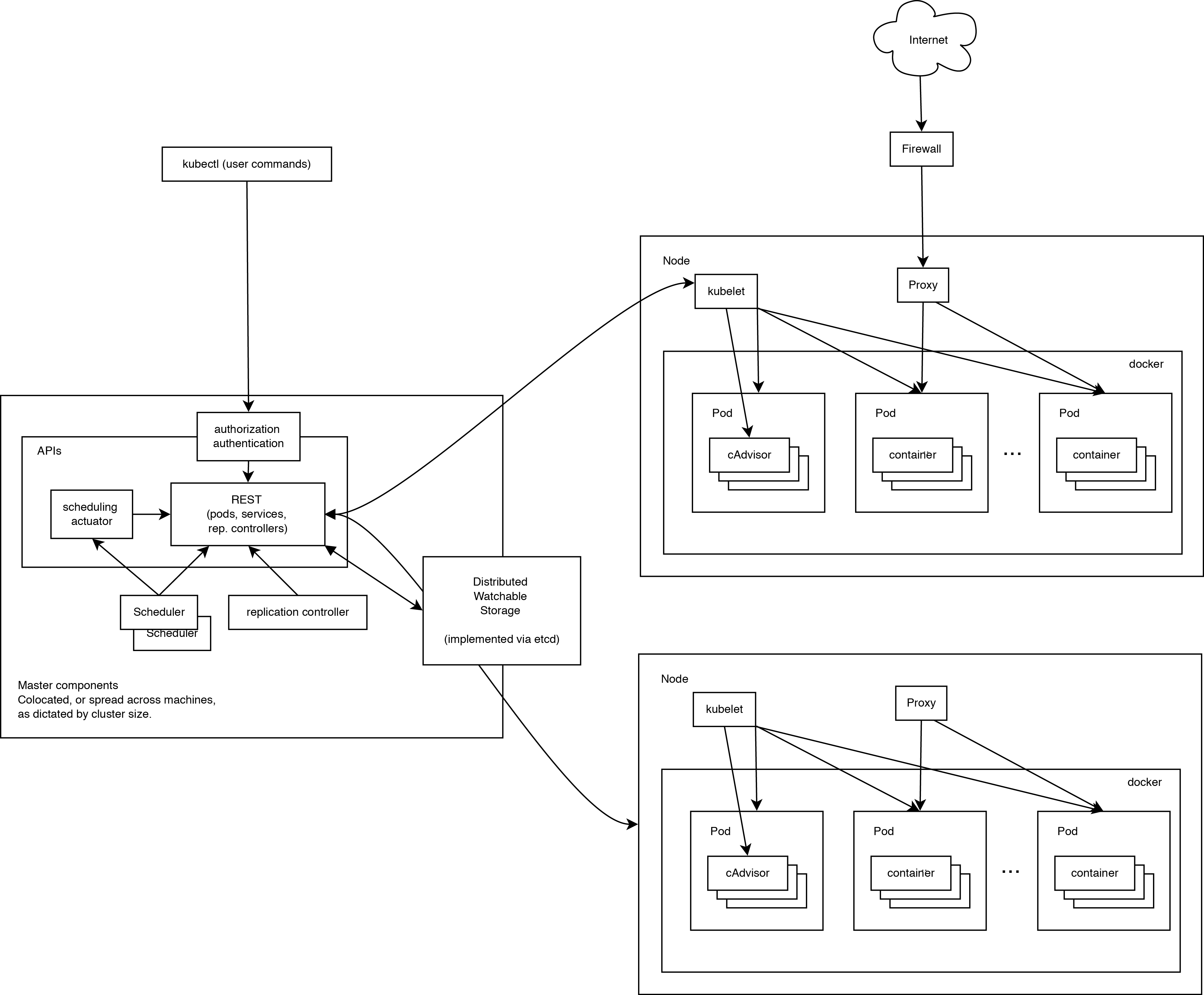
When looking at the architecture of the system, we can break it down into services that work on each node and services of the cluster management level. On each Kubernetes node, the services necessary for managing the node from the wizard and for launching applications are launched. Of course, Docker is launched on each node. Docker provides image loading and container launching.
Kubelet manages pods by their containers, images, partitions, etc.
Also, a simple proxy balancer is launched on each node. This service runs on each node and is configured in the Kubernetes API. Kube-Proxy can perform the simplest redirection of TCP and UDP streams (round robin) between a set of backends.
Kubernetes management system is divided into several components. At the moment, all of them are running on the master node, but soon it will be changed to be able to create a failover cluster. These components work together to provide a single view of the cluster.
The state of the wizard is stored in an instance of etcd. This ensures reliable storage of configuration data and timely notification of other components about a state change.
Kubernetes API provides the api server. It is intended to be a CRUD server with built-in business logic implemented in separate components or in plug-ins. It mainly handles REST operations, checking them and updating the corresponding objects in etcd (and events in other repositories).
Scheduler binds non-running pods to nodes via a / binding API call. Scheduler connect; support for multiple schedulers and custom schedulers is planned.
All other cluster-level functions are provided in the Controller Manager. For example, nodes are discovered, managed, and controlled by the node controller. This entity can ultimately be divided into separate components to make them independently connected.
ReplicationController is a pod-based API engine. Ultimately, it is planned to transfer it to a common plug-in mechanism when it is implemented.
Ubuntu-server 14.10 was chosen as the platform for the example of configuration as the simplest for the example and, at the same time, allowing to demonstrate the basic cluster configuration parameters.
To create a test cluster, three machines for creating nodes and a separate machine for remote installation will be used. You can not select a separate machine and install from one of the nodes.
List of used machines:
You can install Docker according to an article in official sources :
Additional configuration of Docker after installation is not needed, because will be produced by the Kubernetes installation script.
Install bridge-utils:
We execute on the machine from which the installation script will be launched.
If the keys have not yet been created, create them:
We copy the keys to remote machines, after making sure that they have the necessary user, in our case core.
Next, we will install directly Kubernetes. To do this, first of all, download and unpack the latest available release from GitHub:
Kubernetes is configured through standard sample scripts completely before installation is done through configuration files. During installation, we will use the scripts in the ./cluster/ubuntu/ folder.
First of all, we will modify the script ./cluster/ubuntu/build.sh which downloads and prepares the Kubernetes, etcd and flannel binaries necessary for installation:
In order to use the latter, at the time of writing, release 0.17.0 must be replaced:
On the:
And run:
Next, we indicate the parameters of the future cluster, for which we edit the file ./config-default.sh:
This completes the setup and you can proceed to the installation.
First of all, you need to tell the system about our ssh-agent and use the ssh-key for this we do:
Next, go directly to the installation. To do this, use the script ./kubernetes/cluster/kube-up.sh which must be specified that we use ubuntu.
During installation, the script will require a sudo password for each node. At the end of the installation, it will check the status of the cluster and display a list of nodes and Kubernetes api addresses.
Let's see what nodes and services are present in the new cluster:
We see a list of installed nodes in Ready state and two pre-installed services kubernetes and kubernetes-ro - this is a proxy for direct access to the Kubernetes API. Like any Kubernetes service, kubernetes and kubernetes-ro can be accessed directly by IP address from any of the nodes.
To start the service, you need to prepare a docker container, on the basis of which the service will be created. In order not to complicate, the example will use the public nginx container. Obligatory components of the service are the Replication Controller, which ensures that the necessary set of containers (more precisely, pod) is launched and service, which determines which IP address and ports the service and the rules for distributing requests between pods will listen to.
Any service can be launched in 2 ways: manually and using the config file. Consider both.
Let's start by creating a Replication Controller:
Where:
Let's see what we got:
A Replication Controller was created with the name nginx and the number of replicas is 6. Replicas are randomly run on nodes, the location of each pod is indicated in the HOST column.
The conclusion may differ from that given in some cases, for example:
Next, create a service that will use our Replication Controller as a backend.
For http:
And for https:
Where:
Check the result:
To check the neglect, you can go to any of the nodes and execute it in the console:
In curl output, we’ll see the standard nginx welcome page. Done, the service is up and running.
For this startup method, you must create configs for the Replication Controller and service. Kubernetes accepts configs in yaml and json formats. Yaml is closer to me therefore we will use it.
First we clean our cluster from the previous experiment:
nginx_rc.yaml
Apply the config:
Check the result:
A Replication Controller was created with the name nginx and the number of replicas is 6. Replicas are randomly run on nodes, the location of each pod is indicated in the HOST column.
nginx_service.yaml
You may notice that when using the config several ports can be assigned to one service.
Apply the config:
Check the result:
To check the neglect, you can go to any of the nodes and execute it in the console:
In curl output, we’ll see the standard nginx welcome page.
As a conclusion, I want to describe a couple of important points that I had to stumble upon when designing a system. They were connected with the work of kube-proxy, the very module that allows you to turn a disparate set of elements into a service.
PORTAL_NET. The essence is interesting in itself, I propose to get acquainted with how it is implemented.
A short dig led me to the realization of a simple but effective model, take a look at the output of iptables-save:
All requests to the IP address of the service that got into iptables are wrapped on the port on which kube-proxy listens. In this regard, one problem arises: Kubernetes, by itself, does not solve the problem of communication with the user. Therefore, you have to solve this issue by external means, for example:
SOURCE IP Same. when setting up the nginx service, I had to face an interesting problem. It looked like a line in the manual: “Using the kube-proxy obscures the source-IP of a packet accessing a Service”. Literally, when using kube-proxy, it hides the source address of the package, which means that all processing built on the basis of source-IP will have to be done before using kube-proxy.
That's all, thanks for your attention
. Unfortunately, all the information that I want to convey cannot be fit into one article.
What is Kubernetes?
Kubernetes is an open source project designed to manage the Linux container cluster as a single system. Kubernetes manages and runs Docker containers on a large number of hosts, as well as co-hosting and replicating a large number of containers. The project was started by Google and is now supported by many companies, including Microsoft, RedHat, IBM and Docker.
Google has been using container technology for over a decade. She began by launching more than 2 billion containers in one week. With the help of the Kubernetes project, the company shares its experience in creating an open platform designed for scalable container launch.
The project has two goals. If you use Docker containers, the following question arises about how to scale and run containers immediately on a large number of Docker hosts, and how to balance them. The project proposes a high-level API that defines the logical grouping of containers, which allows you to define container pools, balance the load, and also specify their location.
Kubernetes Concepts
Nodes ( node.md ): A node is a machine in a Kubernetes cluster.
Pods ( pods.md ): Pod is a group of containers with shared partitions that run as a unit.
Replication Controllers ( replication-controller.md ): replication controller ensures that a certain number of "replicas" pods are launched at any given time.
Services ( services.md ): A service in Kubernetes is an abstraction that defines a logical unified set of pods and an access policy for them.
Volumes ( volumes.md ): Volume (section) is a directory, possibly with data in it, which is available in the container.
Labels (labels.md ): Labels are key / value pairs that are attached to objects, such as pods. Labels can be used to create and select sets of objects.
Kubectl Command Line Interface ( kubectl.md ): kubectl command line interface for managing Kubernetes.
Kubernetes Architecture
A working Kubernetes cluster includes an agent running on nodes (kubelet) and wizard components (APIs, scheduler, etc), on top of a distributed storage solution. The above diagram shows the desired, in the end, state, although some things are still being worked on, for example: how to make kubelet (all components, in fact) run independently in the container, which will make the scheduler 100% connectable.
Noda Kubernetes
When looking at the architecture of the system, we can break it down into services that work on each node and services of the cluster management level. On each Kubernetes node, the services necessary for managing the node from the wizard and for launching applications are launched. Of course, Docker is launched on each node. Docker provides image loading and container launching.
Kubelet
Kubelet manages pods by their containers, images, partitions, etc.
Kube-proxy
Also, a simple proxy balancer is launched on each node. This service runs on each node and is configured in the Kubernetes API. Kube-Proxy can perform the simplest redirection of TCP and UDP streams (round robin) between a set of backends.
Kubernetes Management Components
Kubernetes management system is divided into several components. At the moment, all of them are running on the master node, but soon it will be changed to be able to create a failover cluster. These components work together to provide a single view of the cluster.
etcd
The state of the wizard is stored in an instance of etcd. This ensures reliable storage of configuration data and timely notification of other components about a state change.
Kubernetes API Server
Kubernetes API provides the api server. It is intended to be a CRUD server with built-in business logic implemented in separate components or in plug-ins. It mainly handles REST operations, checking them and updating the corresponding objects in etcd (and events in other repositories).
Scheduler
Scheduler binds non-running pods to nodes via a / binding API call. Scheduler connect; support for multiple schedulers and custom schedulers is planned.
Kubernetes Controller Manager Server
All other cluster-level functions are provided in the Controller Manager. For example, nodes are discovered, managed, and controlled by the node controller. This entity can ultimately be divided into separate components to make them independently connected.
ReplicationController is a pod-based API engine. Ultimately, it is planned to transfer it to a common plug-in mechanism when it is implemented.
Cluster setup example
Ubuntu-server 14.10 was chosen as the platform for the example of configuration as the simplest for the example and, at the same time, allowing to demonstrate the basic cluster configuration parameters.
To create a test cluster, three machines for creating nodes and a separate machine for remote installation will be used. You can not select a separate machine and install from one of the nodes.
List of used machines:
- Conf
- Node1: 192.168.0.10 - master, minion
- Node2: 192.168.0.11 - minion
- Node3: 192.168.0.12 - minion
Node preparation
Requirements for launching:
- Docker version 1.2+ and bridge-utils are installed on all nodes
- All machines are connected to each other, there is no need for access to the Internet (in this case, you must use the local docker registry)
- All nodes can be entered without entering a login / password, using ssh keys
Installing software on nodes
You can install Docker according to an article in official sources :
node% sudo apt-get update $ sudo apt-get install wget
node% wget -qO- https://get.docker.com/ | sh
Additional configuration of Docker after installation is not needed, because will be produced by the Kubernetes installation script.
Install bridge-utils:
node% sudo apt-get install bridge-utils
Adding ssh keys
We execute on the machine from which the installation script will be launched.
If the keys have not yet been created, create them:
conf% ssh-keygen
We copy the keys to remote machines, after making sure that they have the necessary user, in our case core.
conf% ssh-copy-id core@192.168.0.10
conf% ssh-copy-id core@192.168.0.11
conf% ssh-copy-id core@192.168.0.12
Install Kubernetes
Next, we will install directly Kubernetes. To do this, first of all, download and unpack the latest available release from GitHub:
conf% wget https://github.com/GoogleCloudPlatform/kubernetes/releases/download/v0.17.0/kubernetes.tar.gz
conf% tar xzf ./kubernetes.tar.gz
conf% cd ./kubernetes
Customization
Kubernetes is configured through standard sample scripts completely before installation is done through configuration files. During installation, we will use the scripts in the ./cluster/ubuntu/ folder.
First of all, we will modify the script ./cluster/ubuntu/build.sh which downloads and prepares the Kubernetes, etcd and flannel binaries necessary for installation:
conf% vim ./cluster/ubuntu/build.sh
In order to use the latter, at the time of writing, release 0.17.0 must be replaced:
# k8s
echo "Download kubernetes release ..."
K8S_VERSION="v0.15.0"
On the:
# k8s
echo "Download kubernetes release ..."
K8S_VERSION="v0.17.0"
And run:
conf% cd ./cluster/ubuntu/
conf% ./build.sh #Данный скрипт важно запускать именно из той папки, где он лежит.
Next, we indicate the parameters of the future cluster, for which we edit the file ./config-default.sh:
## Contains configuration values for the Ubuntu cluster
# В данном пункте необходимо указать все ноды будущего кластера, MASTER-нода указывается первой
# Ноды указываются в формате разделитель - пробел
# В качестве пользователя указывается тот пользователь для которого по нодам разложены ssh-ключи
export nodes="core@192.168.0.10 core@192.168.0.10 core@192.168.0.10"
# Определяем роли нод : a(master) или i(minion) или ai(master и minion), указывается в том же порядке, что и ноды в списке выше.
export roles=("ai" "i" "i")
# Определяем количество миньонов
export NUM_MINIONS=${NUM_MINIONS:-3}
# Определяем IP-подсеть из которой, в последствии будут выделяться адреса для сервисов.
# Выделять необходимо серую подсеть, которая не будет пересекаться с имеющимися, т.к. эти адреса будут существовать только в пределах каждой ноды.
#Перенаправление на IP-адреса сервисов производится локальным iptables каждой ноды.
export PORTAL_NET=192.168.3.0/24
#Определяем подсеть из которой будут выделяться подсети для создания внутренней сети flannel.
#flannel по умолчанию выделяет подсеть с маской 24 на каждую ноду, из этих подсетей будут выделяться адреса для Docker-контейнеров.
#Подсеть не должна пересекаться с PORTAL_NET
export FLANNEL_NET=172.16.0.0/16
# Admission Controllers определяет политику доступа к объектам кластера.
ADMISSION_CONTROL=NamespaceLifecycle,NamespaceAutoProvision,LimitRanger,ResourceQuota
# Дополнительные параметры запуска Docker. Могут быть полезны для дополнительных настроек
# например установка --insecure-registry для локальных репозиториев.
DOCKER_OPTS=""
This completes the setup and you can proceed to the installation.
Installation
First of all, you need to tell the system about our ssh-agent and use the ssh-key for this we do:
eval `ssh-agent -s`
ssh-add /путь/до/ключа
Next, go directly to the installation. To do this, use the script ./kubernetes/cluster/kube-up.sh which must be specified that we use ubuntu.
conf% cd ../
conf% KUBERNETES_PROVIDER=ubuntu ./kube-up.sh
During installation, the script will require a sudo password for each node. At the end of the installation, it will check the status of the cluster and display a list of nodes and Kubernetes api addresses.
Script output example
Starting cluster using provider: ubuntu
... calling verify-prereqs
... calling kube-up
Deploying master and minion on machine 192.168.0.10
<Список копируемых файлов>
[sudo] password to copy files and start node:
etcd start/running, process 16384
Connection to 192.168.0.10 closed.
Deploying minion on machine 192.168.0.11
<Список копируемых файлов>
[sudo] password to copy files and start minion:
etcd start/running, process 12325
Connection to 192.168.0.11 closed.
Deploying minion on machine 192.168.0.12
<Список копируемых файлов>
[sudo] password to copy files and start minion:
etcd start/running, process 10217
Connection to 192.168.0.12 closed.
Validating master
Validating core@192.168.0.10
Validating core@192.168.0.11
Validating core@192.168.0.12
Kubernetes cluster is running. The master is running at:
http://192.168.0.10
... calling validate-cluster
Found 3 nodes.
1 NAME LABELS STATUS
2 192.168.0.10 Ready
3 192.168.0.11 Ready
4 192.168.0.12 Ready
Validate output:
NAME STATUS MESSAGE ERROR
etcd-0 Healthy {"action":"get","node":{"dir":true,"nodes":[{"key":"/coreos.com","dir":true,"modifiedIndex":11,"createdIndex":11},{"key":"/registry","dir":true,"modifiedIndex":5,"createdIndex":5}],"modifiedIndex":5,"createdIndex":5}}
nil
controller-manager Healthy ok nil
scheduler Healthy ok nil
Cluster validation succeeded
Done, listing cluster services:
Kubernetes master is running at http://192.168.0.10:8080
Let's see what nodes and services are present in the new cluster:
conf% cp ../kubernetes/platforms/linux/amd64/kubectl /opt/bin/
conf% /opt/bin/kubectl get services,minions -s "http://192.168.0.10:8080"
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP
NAME LABELS STATUS
192.168.0.10 Ready
192.168.0.11 Ready
192.168.0.12 Ready
We see a list of installed nodes in Ready state and two pre-installed services kubernetes and kubernetes-ro - this is a proxy for direct access to the Kubernetes API. Like any Kubernetes service, kubernetes and kubernetes-ro can be accessed directly by IP address from any of the nodes.
Test service launch
To start the service, you need to prepare a docker container, on the basis of which the service will be created. In order not to complicate, the example will use the public nginx container. Obligatory components of the service are the Replication Controller, which ensures that the necessary set of containers (more precisely, pod) is launched and service, which determines which IP address and ports the service and the rules for distributing requests between pods will listen to.
Any service can be launched in 2 ways: manually and using the config file. Consider both.
Manual service start
Let's start by creating a Replication Controller:
conf% /opt/bin/kubectl run-container nginx --port=80 --port=443 --image=nginx --replicas=6 -s "http://192.168.0.10:8080"
Where:
- nginx is the name of the future rc
- --port - ports on which rc containers will listen
- --image - the image from which the containers will be launched
- --replicas = 6 - number of replicas
Let's see what we got:
/opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080"
Conclusion
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
nginx-3gii4 172.16.58.4 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 9 seconds
nginx-3xudc 172.16.62.6 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-igpon 172.16.58.6 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-km78j 172.16.58.5 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-sjb39 172.16.83.4 192.168.0.12/192.168.0.12 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-zk1wv 172.16.62.7 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx nginx nginx run-container=nginx 6
A Replication Controller was created with the name nginx and the number of replicas is 6. Replicas are randomly run on nodes, the location of each pod is indicated in the HOST column.
The conclusion may differ from that given in some cases, for example:
- Part of pod is in pending state: this means that they have not started yet, you need to wait a bit
- Pod has no HOST defined: this means that scheduler has not yet assigned a node on which pod will be launched
Next, create a service that will use our Replication Controller as a backend.
For http:
conf% /opt/bin/kubectl expose rc nginx --port=80 --target-port=80 --service-name=nginx-http -s "http://192.168.0.10:8080"
And for https:
conf% /opt/bin/kubectl expose rc nginx --port=443 --target-port=443 --service-name=nginx-https -s "http://192.168.0.10:8080"
Where:
- rc nginx - type and name of the resource used (rc = Replication Controller)
- --port - port on which the service will “listen”
- --target-port - port of the container to which requests will be broadcast
- --service-name - future service name
Check the result:
/opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080"
Conclusion
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx nginx nginx run-container=nginx 6
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP
nginx-http run-container=nginx 192.168.3.66 80/TCP
nginx-https run-container=nginx 192.168.3.172 443/TCP
To check the neglect, you can go to any of the nodes and execute it in the console:
node% curl http://192.168.3.66
In curl output, we’ll see the standard nginx welcome page. Done, the service is up and running.
Starting a service using configs
For this startup method, you must create configs for the Replication Controller and service. Kubernetes accepts configs in yaml and json formats. Yaml is closer to me therefore we will use it.
First we clean our cluster from the previous experiment:
conf% /opt/bin/kubectl delete services nginx-http nginx-https -s "http://192.168.0.10:8080"
conf% /opt/bin/kubectl stop rc nginx -s "http://192.168.0.10:8080"
Теперь приступим к написанию конфигов.
nginx_rc.yaml
content
apiVersion: v1beta3
kind: ReplicationController
# Указываем имя ReplicationController
metadata:
name: nginx-controller
spec:
# Устанавливаем количество реплик
replicas: 6
selector:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
containers:
#Описываем контейнер
- name: nginx
image: nginx
#Пробрасываем порты
ports:
- containerPort: 80
- containerPort: 443
livenessProbe:
# включаем проверку работоспособности
enabled: true
type: http
# Время ожидания после запуска pod'ы до момента начала проверок
initialDelaySeconds: 30
TimeoutSeconds: 5
# http проверка
httpGet:
path: /
port: 80
portals:
- destination: nginx
Apply the config:
conf% /opt/bin/kubectl create -f ./nginx_rc.yaml -s "http://192.168.0.10:8080"
Check the result:
conf% /opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080"
Conclusion
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
nginx-controller-0wklg 172.16.58.7 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-2jynt 172.16.58.8 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-8ra6j 172.16.62.8 192.168.0.10/192.168.0.10 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-avmu8 172.16.58.9 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-ddr4y 172.16.83.7 192.168.0.12/192.168.0.12 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-qb2wb 172.16.83.5 192.168.0.12/192.168.0.12 name=nginx Running About a minute
nginx nginx Running About a minute
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx-controller nginx nginx name=nginx 6
A Replication Controller was created with the name nginx and the number of replicas is 6. Replicas are randomly run on nodes, the location of each pod is indicated in the HOST column.
nginx_service.yaml
Content
apiVersion: v1beta3
kind: Service
metadata:
name: nginx
spec:
publicIPs:
- 12.0.0.5 # IP который будет присвоен сервису помимо автоматически назначенного.
ports:
- name: http
port: 80 #порт на котором будет слушать сервис
targetPort: 80 порт контейнера на который будет производиться трансляция запросов
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
selector:
name: nginx # поле должно совпадать с аналогичным в конфиге ReplicationController
You may notice that when using the config several ports can be assigned to one service.
Apply the config:
conf% /opt/bin/kubectl create -f ./nginx_service.yaml -s "http://192.168.0.10:8080"
Check the result:
/opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080"
Conclusion
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx-controller nginx nginx name=nginx 6
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP
nginx name=nginx 192.168.3.214 80/TCP
12.0.0.5 443/TCP
To check the neglect, you can go to any of the nodes and execute it in the console:
node% curl http://192.168.3.214
node% curl http://12.0.0.5
In curl output, we’ll see the standard nginx welcome page.
Marginal notes
As a conclusion, I want to describe a couple of important points that I had to stumble upon when designing a system. They were connected with the work of kube-proxy, the very module that allows you to turn a disparate set of elements into a service.
PORTAL_NET. The essence is interesting in itself, I propose to get acquainted with how it is implemented.
A short dig led me to the realization of a simple but effective model, take a look at the output of iptables-save:
-A PREROUTING -j KUBE-PORTALS-CONTAINER
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -j KUBE-PORTALS-HOST
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 10.0.42.0/24 ! -o docker0 -j MASQUERADE
-A KUBE-PORTALS-CONTAINER -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j REDIRECT --to-ports 46041
-A KUBE-PORTALS-CONTAINER -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j REDIRECT --to-ports 58340
-A KUBE-PORTALS-HOST -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j DNAT --to-destination 172.16.67.69:46041
-A KUBE-PORTALS-HOST -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j DNAT --to-destination 172.16.67.69:58340
All requests to the IP address of the service that got into iptables are wrapped on the port on which kube-proxy listens. In this regard, one problem arises: Kubernetes, by itself, does not solve the problem of communication with the user. Therefore, you have to solve this issue by external means, for example:
- gcloud - paid development from Google
- bgp - using subnet announcement
- IPVS
- and other options, which are many
SOURCE IP Same. when setting up the nginx service, I had to face an interesting problem. It looked like a line in the manual: “Using the kube-proxy obscures the source-IP of a packet accessing a Service”. Literally, when using kube-proxy, it hides the source address of the package, which means that all processing built on the basis of source-IP will have to be done before using kube-proxy.
That's all, thanks for your attention
. Unfortunately, all the information that I want to convey cannot be fit into one article.